| Accueil • Rapports d'activités • Rapport d'activités 2001 • Réalité virtuelle et vision artificielle |
| Réalité virtuelle et vision artificielle |
Thèmes scientifiques :
*Réalité Virtuelle et Réalité Augmentée
mots clés : téléopération via Internet, réalité augmentée, retour haptique, réalité virtuelle.
mots clés : Calibration de caméras et de télémètres, analyse dimage 2D (textures) et 3D, modélisation et reconstruction 3D, appariement 2D/3D.
mots clés: Calibration, effet dempreinte, capteurs multimodes binoculaire et multi-aural, communication, traitement de données.
Responsables : Florent Chavand
Malik Mallem (Réalité Virtuelle et Réalité Augmentée)
Sylvie Lelandais (Vision 2D/3D)
Etienne Colle (Capteurs intelligents)
Participants :
Nazim Agoulmine Pr U. Evry : (depuis Octobre 2000)
Christian Barat MCF U. Evry : (depuis Octobre 1997)
Florent Chavand Pr U. Evry : (depuis 1992)
Paul Checchin MCF U. Evry : (depuis Septembre 1997)
Etienne Colle Pr U. Evry : (depuis 1992)
Abderrahman Kheddar MCF U. Evry : (depuis 1998)
Sylvie Lelandais-Bonadé MCF IUT Evry : (depuis 1992)
Malik Mallem Pr U. Evry : ( depuis 1992)
David Roussel MCF IIE-CNAM : (depuis Septembre. 2000)
Jean Triboulet MCF IUFM Versailles : (depuis Septembre 1996)
Doctorants :
Naima Aitoufrouk : 10/99 : Bourse algérienne
Hichem Arioui : 10/99 : Bourse algérienne
Fakheddine Ababsa : 10/99 : ATER
Merad Djamel : 10/00 : Allocation U. Evry
Danielo Goncalves : 10/00 : Bourse brésilienne
Stéphane Redon : 09/99 : Bourse AMX
Thèses soutenues ( 97-00) :
Hafid Hamadène : 09/98 : Ingénieur (USA)
Humberto Loaïza : 11/99 : Enseignant Chercheur Univ. de Valle (Colombie)
Sébastien Rougeaux : 03/99 : Ingénieur (Australie)
Mudar Shaheen : 04/99 : Ingénieur (France)
Laurent Boutté : 11/00 : Ingénieur informaticien
Djamel Hanifi : 03/00 : Ingénieur
Samir Otmane : 12/00 : Post-doc U. Evry
Coopérations et Groupes de travail :
GDR ISIS
ETL / MITI Japon : Calibration de caméras, Optiques grand champ angulaire, Poursuite dobjets par vision (effectuée jusqu en 1999).
CEA/STR , LRP : Laboratoire Commun pour la Téléopération et la Réalité Virtuelle (LCTRV).
LAMI : Université dEvry et Université de Valle ( Colombie) : Robocup98.
LASMEA (Université de Clermont-Ferrand) : Relevés 3D.
IMASSA ( Brétigny) : Reconnaissance de lorientation de surfaces texturées
INT Evry : Parallélisation dalgorithmes de vision.
Renault (RVI) : Conduite de poids lourds en convoi. Etude dun système de localisation dun véhicule suiveur.
Renault Automation : Supervision dune machine à usinage rapide par vision.
INRIA Roquencourt : Projet Interaction 3D (I3D).
ADDS-Concept : Prétraitements et binarisation dimages de pastilles de bouteilles de gaz.
Institut Automatic Control (Université de Munich) : Réalité Virtuelle pour la Téléopération
INTRODUCTION
Notre laboratoire a été le premier en France à développer des études sur le concept de Réalité Augmentée pour le contrôle des robots téléopérés (thèse de Malik Mallem : Aide à la perception en Téléopération. Superposition à une image caméra d'une image synthétique animée en temps réel à partir d'informations capteurs, 24 Avril 1990). Cet axe de recherche sest poursuivi avec le développement du système MCIT (Module de Contrôle et dInterface en Téléopération). Nous sommes le laboratoire français le plus avancé dans la mise en uvre du concept de Réalité Augmentée avec des images " live " pour la téléopération. Ce système a été étendu afin de permettre la téléopération d'un robot via Internet en mettant en uvre un concept nouveau de guides virtuels. Celui-ci permet d'assister l'opérateur dans la perception et la commande à distance du robot. Ces assistances ont pour objectif l'amélioration de la précision et de la sécurité du déroulement de la tâche (thèse de Samir Otmane, dec. 2000)[OTM00T].
La base de la Réalité augmentée est la superposition de lenvironnement réel et de lenvironnement reconstitué (virtuel). Cest une des techniques de la Réalité Virtuelle (RV).
Moyennant des interfaces et des dispositifs ergonomiques adaptés aux modalités sensoriels de lopérateur humain, linteraction entre lopérateur et un environnement virtuel (EV) est voulue à la fois multimodale (incluant le retour haptique i.e. la kinesthésie et le tactile) et intuitive. Ainsi, linteraction haptique (i.e. interaction mettant en jeux le sens haptique de lhomme) avec un environnement virtuel rentre dans un domaine plus large que celui de la téléopération. Cest donc tout naturellement que les travaux de recherche dans ce domaine couvrent un spectre dapplications plus large : le prototypage virtuel, la téléopération, les simulateurs interactifs et plus généralement les interfaces hommes machines haptiques.
La mise en uvre dun système de Réalité Augmentée (RA) nécessite la modélisation de lenvironnement du robot. Cette modélisation réalisée par des capteurs télémétriques, par des caméras a suscité dans notre laboratoire la naissance et le développement dactivités en Vision artificielle lune orientée capteurs - Capteurs intelligents -, lautre orientée traitement des données issues de ces capteurs - Vision 2D/3D -. Lobjectif étant détudier de nouveaux capteurs, des méthodes de calibration de systèmes multicapteurs, des méthodes de segmentation robustes, opérationnels dans des environnements difficiles avec images fortement dégradées, et devant conduire à la modélisation denvironnements " tels que construits ".
Dans le sous thème Vision 2D/3D des méthodes de calibration robustes pour ces capteurs pris séparément ou groupés dans un système multicapteur ont été étudiées. Lanalyse et la segmentation dimages de texture ont donné lieu à un travail important. Lobjectif est de conduire à des segmentations robustes opérationnelles dans des environnements avec images fortement dégradées. Un ensemble doutils et de méthodes de modélisation, de reconstruction 3D et dappariement 2D/3D ont été étudiés et développés pour la modélisation denvironnements domestiques.
Pour les capteurs intelligents, les travaux ont porté sur la modélisation de capteurs télémétriques laser ou ultrasonores, sur le développement de capteurs à faible coût destinés à la robotique de service et sur la technologie des moyens de traitement et de communication.
Ces trois sous thèmes sont fortement liés. Le premier intitulé " Réalité virtuelle et réalité augmentée " concerne létude et le développement des interfaces homme-machine. Le second intitulé " Vision 2D-3D " a pour objectif, lélaboration de méthodes de modélisation et calibration des capteurs utilisés, de modélisation 2D-3D denvironnement, dappariement dimages et leurs modèles 3D et de recalage 3D. Ces méthodes sont utilisées dans le sous thème 1 (§2.1.). Le dernier sous thème " Capteurs intelligents " (§2.3.) concerne le développement de capteurs destinés à la robotique de service autour de capteurs ultrasonores ou de caméras vidéo et sur la technologie des moyens de traitement et de communication. Ces capteurs sont utiles pour la modélisation denvironnement traités dans le sous thème 2 (§2.2.).
2.1. REALITE VIRTUELLE ET REALITE AUGMENTEE
INTRODUCTION
Les concepts de la Réalité virtuelle et de la réalité augmentée appliqués à la supervision et au contrôle des machines et systèmes complexes conduisent à létude et au développement dInterfaces Homme-Machine avancées mettant en uvre des canaux multisensoriels.
Les développements de l'activité Réalité Virtuelle(RV) et réalité Augmentée(RA) du CEMIF-LSC ont pour application la téléopération et le télétravail. Lenvironnement de travail pouvant être distant, hostile à lhomme. Le site distant est représenté sous forme synthétique (par un environnement virtuel).
Les problèmes de fonds traités sont :
1- Les aspects recouvrement, au sens récupération des erreurs et incidents imprévus et aussi ceux issus du désaccord entre la représentation virtuelle et lenvironnement de travail réel. Par conséquent développer un formalisme et une méthodologie de description des tâches permettant de laisser au système de commande de la machine exécutrice une liberté suffisante pour s'adapter aux incidents rencontrés.
2- Les aspects transformations bilatérales et de représentation proprement dite de lenvironnement de travail en un environnement synthétique avec la possibilité de passer instantanément, éventuellement automatiquement, dune représentation virtuelle à une représentation réelle ou réelle augmentée, sans altérer la tâche en cours.
Ce sous thème est constitué de deux parties complémentaires :
2.1.1. Téléopération et Réalité Augmentée
Dans le domaine de la Téléopération nous avons étudié et développé le système MCIT (Module de Contrôle et dInterface en Téléopération) qui apporte une assistance à la perception de la scène et au contrôle du robot. Son principe repose sur le concept de Réalité Augmentée dans lequel la scène modélisée (monde virtuel) est superposée au monde réel vu par une caméra.
Ce système a été étendu afin de permettre la téléopération d'un robot via linternet en mettant en uvre un concept nouveau de guides virtuels. Celui-ci permet d'assister l'opérateur dans la perception et la commande à distance du robot. Ces assistances ont pour objectif l'amélioration de la précision et de la sécurité du déroulement de la tâche (Thèse de Samir Otmane, dec. 2000).
Les apports de lapproche RA sont multiples :
Nous présentons les deux systèmes de réalité augmentée développés. Le premier est constitué des outils nécessaires à un système de RA et le second est dédié à la téléprogrammation de tâches via linternet. Le second système fait appel, bien entendu, aux services du premier.
2.1.1.1. Le système Multimédia de Contrôle et d'Interface en Téléopération (MCIT)
Un système Multimédia de Contrôle et d'Interface en Téléopération (MCIT) est développé dans notre laboratoire. Il est basé sur l'approche réalité augmentée et a pour but d'apporter à l'opérateur humain, en situation de téléopération ou de supervision de tâche, une assistance à la perception en vision indirecte sur écran vidéo de la scène et une assistance à la commande en désignant un objet directement sur l'écran vidéo.
Ces assistances s'appuient sur deux architectures spécifiques, l'une matérielle et l'autre logicielle. L'architecture matérielle géographiquement répartie est constituée d'un ensemble de capteurs (télémètre et caméra) et de trois calculateurs en réseau. Cette architecture permet l'acquisition du monde réel par le biais de capteurs et la superposition à celui-ci du monde virtuel. La partie logicielle permet de créer, de mettre à jour ce monde virtuel et de le mettre en correspondance avec le monde réel.
MCIT offre à l'opérateur humain une interface graphique conviviale et lui permet d'effectuer une téléprogrammation de niveau tâche. Le monde réel sert d'interface entre l'opérateur humain et le monde virtuel représenté par une BD 3D. La désignation d'un objet, à manipuler par le robot, sur écran vidéo revient alors à le désigner dans le monde virtuel. L'exécution de la tâche peut être simulée en utilisant le monde virtuel avant d'être appliquée au monde réel. Après l'exécution de la tâche, le monde virtuel est superposé au monde réel. C'est l'approche de la réalité augmentée (RA) désignée ainsi car le monde réel est l'interface entre l'opérateur et le monde virtuel.
L'approche de la réalité augmentée permet davoir une vue, en permanence, du monde réel. Contrairement à l'approche réalité virtuelle intégrale, la RA ne nécessite pas un graphique réaliste, une représentation fil de fer suffit. Car, les deux mondes étant superposés, il faut masquer le moins possible l'image vidéo. Par ailleurs, cette représentation fil de fer permet à l'opérateur de percevoir l'image vidéo même quand celle-ci est partiellement dégradée et donc, de continuer la tâche. De plus, cette approche permet de réaliser une commande de niveau objet car elle associe à un objet réel sa BD 3D [CHA98aC], [CHA98bC].
Architecture générale du système MCIT
Dans la station de contrôle commande, l'opérateur humain utilise un seul écran vidéo. Sur celui-ci est superposée une représentation graphique de la scène sur son image caméra. A partir de cet écran, l'opérateur humain peut percevoir la scène distante et agir à distance sur celle-ci. En effet, il commande les capteurs pour réaliser le relevé 3D -nécessaire à la création de la base de données 3D- ou la reconstruction 3D, et le robot pour l'exécution de tâche.
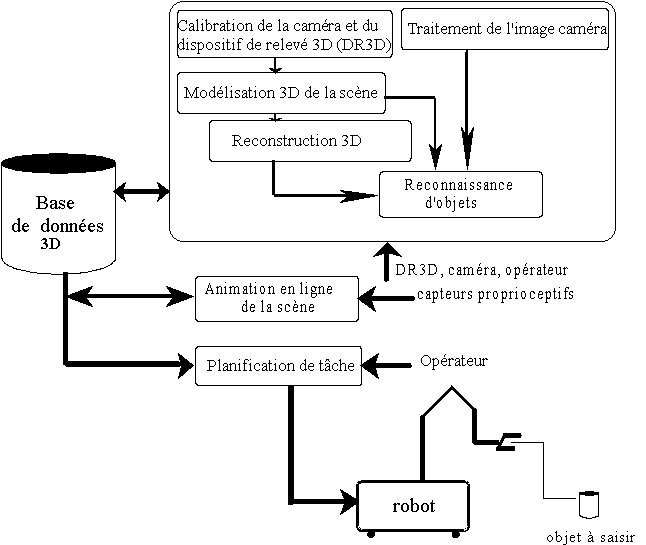
Le site distant est équipé de capteurs extéroceptifs, dispositif de relevé 3D (DR3D) et caméra, et proprioceptifs qui renseignent en ligne sur la configuration du robot. Cette architecture permet l'acquisition du monde réel par le biais de capteurs et la superposition à celui-ci du monde virtuel. La partie logicielle permet de créer, de mettre à jour ce monde virtuel et de le mettre en correspondance avec le monde réel (Figure II.1).
Figure II.1 : Architecture fonctionnelle du système MCIT
Les principaux modules logiciels sont présentés brièvement.
Pour que la superposition d'images puisse être effectuée correctement, il faut connaître la transformation mathématique qui fait passer des coordonnées tridimensionnelles de lobjet aux coordonnées bidimensionnelles de son image et vice-versa. Cette transformation est obtenue par la calibration de la caméra.
Pour l'acquisition des données géométriques 3D de l'environnement, il faut également calibrer le dispositif de relevé 3D (DR3D).
- Module de modélisation 3D et de reconstruction 3D [NZI97R], [MOR97C]
Ce module consiste à construire et mettre à jour la base de données 3D de l'environnement par coopération avec l'opérateur humain.	
Celui-ci est basé sur la modélisation orientée objet. La transformée de Hough, dont une amélioration est apportée, est utilisée pour extraire les segments de droite de limage. Lorganisation perceptive est appliquée pour trouver un modèle 2D de limage
- Module de reconnaissance d'objets [CHA97C], [SHA01R]
Ce module consiste, à partir des modèles 3D fournis par le module de modélisation et du modèle 2D, résultat du traitement de l'image caméra, d'effectuer la mise en correspondance entre ces deux modèles afin de reconnaître les objets modélisés et vus par la caméra.
Le contenu de ces trois modules est décrit dans §2.2.1.1. pour la calibration des capteurs et dans §2.2.2. pour les modélisation et reconstruction 3D et la reconnaissance d'objet.
- Module d'animation
Ce module consiste à collecter les informations proprioceptives du robot et à l'animation, en ligne, de sa représentation synthétique, afin de permettre à l'opérateur de percevoir la scène même si l'image caméra est dégradée.
- Module de planification de tâche
Ce module permet la génération automatique d'une trajectoire 21/2 D d'un bras manipulateur opérant sur un plan de travail sur lequel sont entreposés des objets de faible hauteur. Il permet également de calculer les configurations de saisie par l'effecteur de l'objet désigné par l'opérateur humain sur écran vidéo.
MCIT permet deffectuer des télé-mesures et une reconstruction 3D en ligne de lenvironnement. De plus, MCIT réalise une commande de niveau objet, car il associe à un objet réel sa BD 3D.
Architecture informatique du système MCIT
La station de contrôle commande est constituée de deux calculateurs reliés en réseau Ethernet, dont les modules qu'ils supportent sont mentionnés dans la figure II.2.
Cette architecture répartie est indispensable pour supporter l'ensemble des modules logiciels décrits précédemment. En effet, certains doivent s'exécuter en parallèle tels que les modules de perception de l'environnement et ceux de commande du robot.
Les différents logiciels organisés en client/serveur communiquent entre-eux via Internet, en utilisant les sockets selon les protocoles TCP/IP.

Figure II.2 : Architecture informatique du système MCIT
Ce système fait l'objet, actuellement, d'une application dans le cadre d'un contrat de recherche développement avec l'entreprise Renault - Automation.
Ce contrat est intitulé "Surveillance par vision d'une machine à usinage rapide de type Urane 20 ou Urane 25" et sert de base à la thèse de Djamel Merad encadré par Malik Mallem et Jean Triboulet. Ce travail consiste en la vérification de l'adéquation entre le modèle virtuel de CAO de la pièce à usiner ou dun outil et son image caméra, avant de lancer l'usinage. Les trois phases à accomplir afin de réaliser ce travail sont :
- recalage 3D du modèle CAO de la culasse afin dobtenir une superposition des modèles virtuel et réel.
2.1.1.2. Le système de télétravail robotisé via Internet (ARITI)
INTRODUCTION
Afin de traiter le second problème évoqué dans §2.1., un système de contrôle commande de robot via linternet (ARITI : " Augmented Reality Interface for Teleoperation via Internet" ) a été réalisé dans le cadre de la thèse de Samir Otmane [OTM00T].
Dans cette thèse est présenté létude et la conception dun système pour la téléopération de robots via le réseau Internet. Les recherches réalisées concernent principalement le développement de méthodes et doutils pour linterfaçage efficace dun opérateur dans le cadre de la " téléopération d'un robot via Internet":
De nombreuses expérimentations ont été réalisées pour évaluer dune part, linterface utilisateur et dautre part, larchitecture réseau du système en fonction du nombre de connexions simultanées et de la distance qui sépare les deux sites.
Une démonstration est possible par l'accès au site Web du Cemif Système Complexes dont le serveur a pour adresse : " lsc.univ-evry.fr " par tout calculateur doté du navigateur Netscape / Internetexplorer ou au site de la NASA
" http://ranier.oact.hq.nasa.gov/telerobotics_page/realrobots.html ".
Cet accès permet une visualisation en quasi temps réel de l'image d'un robot du CEMIF-LSC et la télécommande graphique du robot. En effet, le robot et son environnement sont représentés par leur modèle 3D. Les modèles géométriques direct et inverse du robot sont également pris en compte. La désignation sur écran de l'un des composants de la scène équivaut à une désignation dans le modèle 3D. Deux programmes ont été développés, lun correspond au serveur et lautre au client écrit en JAVA. Le serveur a pour rôle de transmettre au client le retour vidéo et dappliquer, au robot réel, les consignes fournies par le client.
Architecture générale du système ARITI
Le système ARITI est constitué de six modules (figure II.3), cinq modules se trouvant du côté du site maître et un module du côté du site esclave. La communication entre les deux sites se fait via le réseau Internetou Intranet.
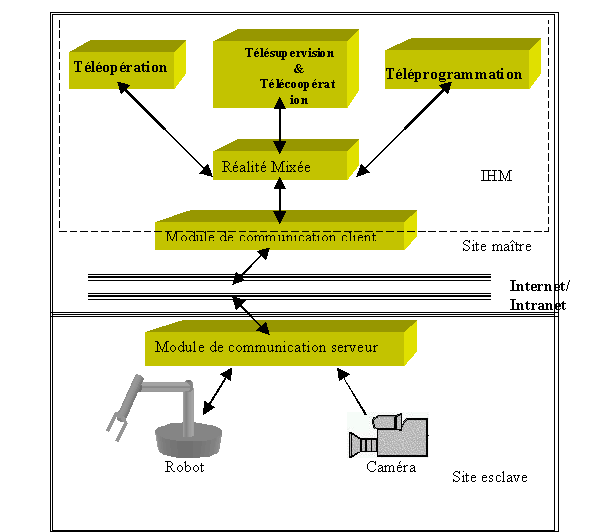
Figure II.3 : Architecture fonctionnelle du système ARITI
Dans le site esclave se trouve un robot et une caméra vidéo ainsi que le module de communication serveur. Ce dernier est constitué de deux serveurs, un pour les images vidéo et un autre pour les consignes robot. Le premier serveur se charge de capturer des images via la carte d'acquisition vidéo, de les compresser et ensuite de les envoyer directement aux différents clients connectés. Le deuxième serveur quant à lui est chargé de récupérer les ordres envoyés par le client et les transmet directement au robot pour exécution (il peut se charger éventuellement de transférer des informations depuis le robot vers le client).
Dans le site maître se trouve un opérateur humain et une machine connectée à Internet. Le premier niveau de description de cette partie se résume en un module de communication client qui permet l'échange d'informations avec le site esclave, et quatre modules constituant l'Interface Homme Machine (IHM) qui gère les interactions entre l'opérateur humain et le module de communication client. Ce dernier contient deux clients, un pour la réception d'images vidéo, décompression et la visualisation et l'autre se charge d'interpréter les actions de l'opérateur et ensuite les envoie sous forme d'ordres au site esclave.
Le module d'IHM permet à l'opérateur de spécifier le mode de travail désiré géré par chacun des modules, Téléopération, Téléprogrammation et Télésupervision & Télécoopération. Chacun de ces trois modules utilise un module central appelé module de Réalité Mixée (RM) qui combine les deux mondes virtuel et réel et qui joue aussi le rôle d'intermédiaire entre les différents modes de travail et le module de communication client.
Architecture informatique du système ARITI
La connexion au système ARITI peut seffectuer de deux manières, indirecte ou directe (figure II.4). Dans le premier cas, lopérateur distant accède au système ARITI via le serveur Web du laboratoire et retrouve ainsi toutes les informations concernant le système ARITI (description du système, fonctionnement, publications résultantes des différents travaux réalisés pour la validation du système, etc.). Dans le second cas (connexion directe), lopérateur utilise directement le système pour téléopérer le robot et réaliser des tâches de manipulation ou tout simplement faire de la simulation. Dans les deux cas le contrôle du robot réel est protégé par un " login " et un " mot de passe ".
![]()
Figure II.4 : Architecture informatique du système ARITI
La modularité et la conception objet du système ARITI, permet son adaptation à plusieurs applications. En effet, deux applications ont été réalisées, une utilisant un robot manipulateur à 4 degrés de liberté (ddl) accessible par Internet. Lautre application utilise un robot mobile autonome dans le cadre dun projet dassistance aux personnes handicapée utilisé actuellement en connexion locale.
Application avec un robot manipulateur
Il sagit du premier robot utilisé pour valider le premier système de téléopération de robot via Internetréalisé en France. Le robot manipulateur se trouvant au CEMIF-LSC est utilisé grâce au système ARITI [OTM00aC] par de nombreux opérateurs dans le monde. Les tâches de télémanipulation sont facilitées par lutilisation des guides virtuels [OTM00bC] fournit par le système en mode de téléopération. En effet, ces guides virtuels améliorent les performances des opérateurs en sécurisant les manipulations, en réduisant les imprécisions et en fin lexécution rapide des tâches.
La figure II.5 montre le contrôle - commande via Internetqui est possible par accès au site Web du Cemif Systèmes Complexes par tout calculateur doté d'un navigateur. Cet accès permet une visualisation en quasi temps réel de l'image d'un robot du CEMIF-LSC et la télécommande du robot.
Application avec un robot mobile
Cette deuxième application est destinée à étudier lapport de la réalité virtuelle et de la réalité augmentée (interface graphique, guides virtuels, superposition dinformations 2D/3D sur une image vidéo, etc.) pour améliorer les performances dune personne handicapée contrainte dutiliser un robot mobile muni dun bras manipulateur [OTM00cC]. Cetta application est développée en collaboration avec léquipe du thème 3.2 (§ 3.2.1.).
La réalisation de linterface homme machine pour cette application a nécessité une mise à jour minimale du système ARITI. En effet, seulement trois modules ont été essentiellement rajoutés, un module contenant les modèles virtuelles du nouvel environnement et du robot et deux autres modules client, serveur pour la communication . Nous présentons dans la figure II.6, linterface de contrôle commande du robot mobile avec utilisation de deux guides virtuels actifs pour aider lopérateur à faire traverser au robot une porte.
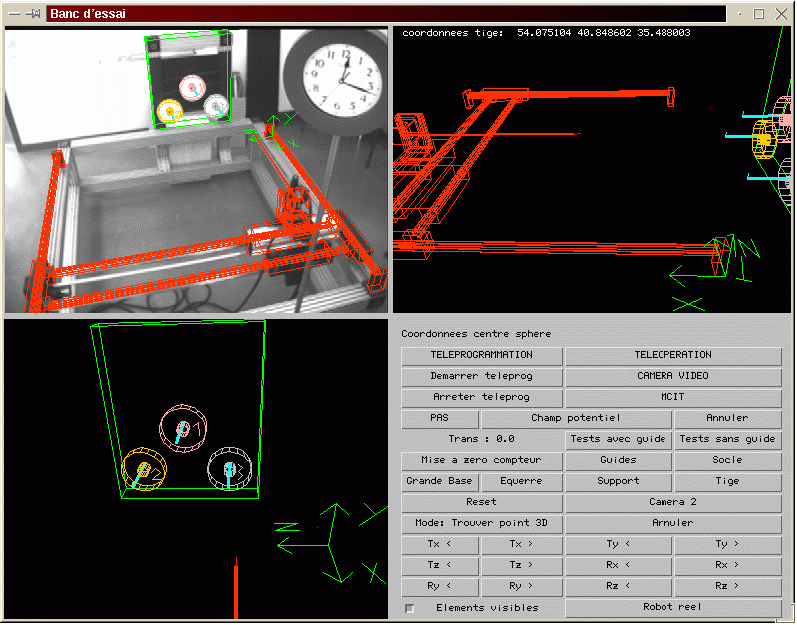
Figure II.5 :Interface de contrôle-commande de robot via linternet
Le système ARITI va être complété par trois fonctionnalités :
Multimodalité:Compléter avec des retours dinformations sonore, tactile, force
Interopérabilité: - Interactions avec dautres systèmes de RV et RA. 		 - Téléopération multi-robot.
Téléconfiguration de lenvironnement réel: Télécalibration de la caméra.
Langage de Télétravail robotisé : Définir un langage de haut niveau pour la programmation et la réalisation de tâches robotique via Internet.
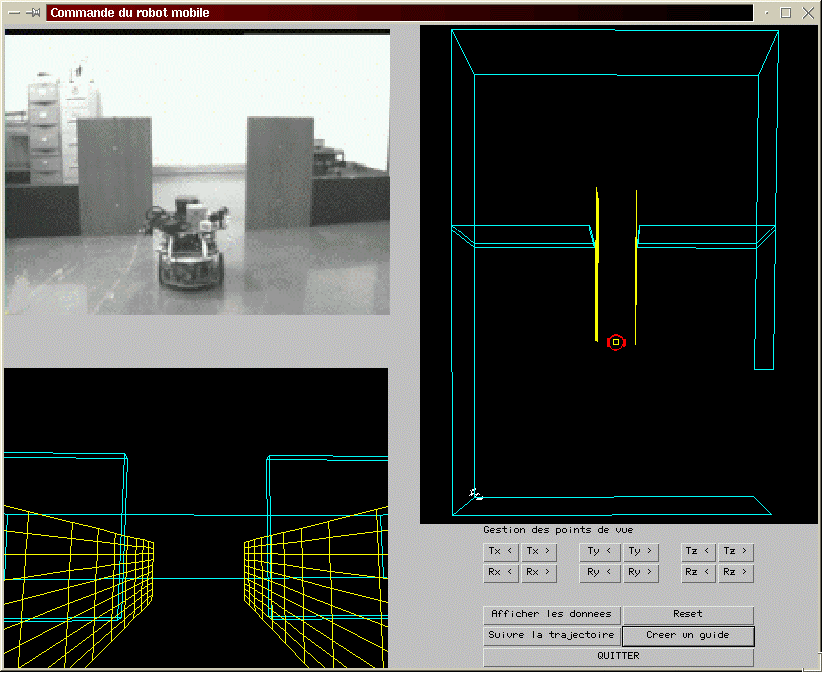
Figure II.6 :Interface de contrôle-commande dun robot mobile avec utilisation
de deux guides virtuels formant un couloir pour le robot.
2.1.2. Réalité virtuelle et rendu haptique
Moyennant des interfaces et des dispositifs ergonomiques adaptés aux modalités sensoriels de lopérateur humain, linteraction entre lopérateur et un environnement virtuel (EV) est voulue à la fois multimodale (incluant le retour haptique i.e. la kinesthésie et le tactile) et intuitive. Ainsi, linteraction haptique (i.e. interaction mettant en jeux le sens haptique de lhomme) avec un environnement virtuel rentre dans un domaine plus large que celui de la téléopération. Cest donc tout naturellement que les travaux de recherche dans ce domaine couvrent un spectre dapplications plus large : le prototypage virtuel, la téléopération, les simulateurs interactifs et plus généralement les interfaces hommes machines haptiques.

Fig. 7 Schéma global dun système à retour haptique
La problématique théorique posée par ces systèmes concerne à la fois linformatique, lautomatique et la psychophysique de laction et de la perception i.e. celle liée aux problèmes de la perception haptique humaine. En effet, il sagit détablir les bases théoriques pour linterconnexion dun opérateur humain, de nature incertain (i.e. paramètres subjectifs, parfois non mesurables), avec un environnement virtuel, de nature discret, via des dispositifs mécatroniques actifs, de nature continus et non linéaires.
Sur les systèmes à retour haptique il existe actuellement deux voies de recherche :
La voie de recherche choisie est naturellement médiane car plusieurs problèmes traités par linformatique trouvent facilement une solution dans la commande et vice-versa. Par conséquent, parmi les thésards encadrés par A. Kheddar (responsable de ce thème) lun (Stéphane Redon) travaille sur les aspects informatiques du retour haptique et lautre, (Hichem Arioui), travaille sur les aspects purement commande. Les résultats sorientent vers des socles de ce qui a été baptisé linfohaptie (par analogie à linfographie).
 Fig. 8 Vers des
API de rendu haptique (infohaptie)
Fig. 8 Vers des
API de rendu haptique (infohaptie)
(EV : Environnement Virtuel, API : Application Programmable Interface)
Un projet commun a été lancé avec lINRIA Rocquencourt (laction I3D dont la responsable INRIA est S. Coquillart) via lequel nous collaborons dans une problématique plus générale de linteraction 3D mettant en uvre des outils de visualisation tels que le Workbench.
La partie informatique dun rendu haptique seffectue en 3 étapes :
Dans le cadre de sa thèse S. Redon développe cette partie. Parmis les résultats obtenus on dénote une nouvelle approche pour la détection de collision (DdC) [REDO00C]. Les algorithmes de DdC utilisés dans les EV sont discrets i.e. la détection se fait après collision, donc après interpénétration, il est alors assez souvent nécessaire deffectuer un retour arrière afin de déterminer le temps de collision entre deux pas de temps et corriger létat des objets virtuels en un état cohérent. Lapproche proposée [REDO00C] est continue et est basée sur linterpolation de la trajectoire par un mouvement continu entre deux pas discret. Il a été choisi des mouvements de vissage dont les paramètres sont calculés pour un objet à chaque pas de la simulation :
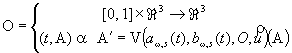
Pour des objets polyédriques (représentation largement adoptée en EV) la collision est réduite à deux détections élémentaires : segment segment et point triangle (ou plan). La formulation développée du problème se réduit, pour chacun des deux cas, à une résolution dun polynôme dordre au plus 3. Lalgorithme envoie précisemment le temps continu et le lieu géométrique de la collision entre 2 pas de temps.
Le problème de réponse aux collisions et animation dynamique est abordé différemment de ce qui est fait traditionellement. En effet, pour lanimation dynamique en EV, les approches proposées par dautres checheurs sont essentiellement basées sur une formulation LCP (problème de complémentarité lineaire) en terme des forces exercées. Contrairement à ces approches (basés sur les travaux virtuels pour la prise en compte des contraintes), le principe de Gauss a été utilisé dans la formulation du même problème en terme de mouvements, et ce sont les accélérations qui sont directement calculées. Lanimation dynamique (incluant la réponse aux collisions) est réduite en un problème purement géométrique et consiste dans la majorité des cas en la résolution dun problème doptimisation où le critère est quadratique en accélérations et où les contraintes dinégalité sont linéaires. Les résultats de ces travaux sont soumis à des publications courant 2001.
Du point de vue de lautomatique, Hichem Arioui est détaché au CEA dans le cadre du LCTRV. Son travail de thèse consiste à développer des algorithmes de commande robustes, dune part, aux fluctuations de la fréquence déchantillonnage (causées par le non détermisme des algorithmes de rendu haptique ; DdC, animation dynamique, etc.) et, dautre part, à la fluctuation des retards de transmission dans les lignes dans le cas où linterface haptique ou lEV est généré par une station de RV distante du site de travail (application au prototypage virtuel en concurrent engineering).
Dautres travaux de recherche en arrière plan concernent le problème délicat du retour tactile. En effet le terme haptique concerne aussi bien la kinesthésie et le tactile. Si pour le premier, des solutions aussi bien technologiques que théoriques existent (car dérivées de la téléopération), il serait pour linstant hasardeux de lancer une thèse dans le domaine tactile si les grandes lignes ne sont pas clairement définies.
Depuis 1999 une collaboration est établie avec lINRETS (groupe de Stéphane Espié) pour étudier des solutions avec retour haptique dans les simulateurs de conduite automobile. Létude soriente plus dans la recherche de métaphores haptiques plutôt que dans les solutions purement technologiques pour un rendu réaliste. Un stagiaire de DEA,Yassine Beroual [BERO00D] est a été pris pour 6 mois afin de définir une première étape de la collaboration et qui correspond à la mise en place dun siège vibrant pour le rendu de sensation qui relèvent plus du tactile que du kinesthésique et dans la continuité un autre stagiaire de DEA RVMSC Hakim Mohellebi est pris cette année pour la continuité des travaux effectués. Ce stage est suivi dune thèse pour la rentrée universitaire 2001 2002.
Une autre collaboration a débuté courant 1999 avec L'Institut Français du Pétrole (IFP). LIFP réalise des applications informatiques pour modéliser le sous-sol à partir de données acquises sur le terrain (sismogrammes, données aux puits, etc). Cette modélisation se traduit par des maillages souvent volumineux (plusieurs millions de mailles) dans lesquels de nombreuses variables physiques scalaires et vectorielles sont calculées. Classiquement, des techniques d'infographie sont utilisées pour visualiser ces résultats de calcul.
Une permière étude a montré la possibilité de lutilisation de la composante haptique comme partie intégrante de l'interface des applications de visualisation [ARAM00S]. Le but des travaux futurs est de parfaire les algorithmes de rendu haptique volumique et de quantifier lapport du rendu haptique pour enrichir les possibilités de perception et de manipulation offertes par cette visualisation multimodale.
Le rendu haptique volumique est une nouvelle voie dinvestigation dans dautres domaine et notamment le domaine médical.
Dans le cadre du projet MATEO, il est prévu la réalisation dun simulateur pour la planification et lentraînement du geste chirurgical lors de pose de prothèses lanévrisme de laorte. Le simulateur comporte une station de travail pour la visualisation et linteraction haptique avec le modèle 3D reconstitué à partir des images de radiologie (IRM) du patient à traiter. Nous avons envisagé de développer un premier prototype sur la base de mdèles surfaciques. Il est alors question deffectuer la reconstruction 3D (i.e. en images de synthèses) dune portion daorte à partir de coupes tomographiques (IRM). Cette reconstruction doit prendre en compte plusieurs contraintes : dune part un aspect interactif afin de manipuler facilement les données. Et dautre part, un aspect dimensionnement, qui doit permettre, à terme de calculer les caractéristiques dune endoprothèse destinée à traiter un anévrisme de laorte. Actuellement, des modèles de corps déformables et biomécaniques adéquats sont testés et éventuellement adaptés afin de satisfaire les contraintes dinteractivité à savoir : le réalisme du rendu et les aspects temps réel. Dans un deuxième temps nous envisageons de reconstituer un modèle de synthèse volumique directement à partir des données IRM. Il est aussi question de concevoir une méthodologie dun rendu haptique interactif à partir de la représentation volumique.
Lanalyse perceptuelle puis la modélisation et reconstruction 3D sont présentées successivement.
2.2.1. Analyse perceptuelle
Les travaux menés autour de ce concept se décomposent en trois parties : la première présente la calibration des différents capteurs utilisés (2D ou 3D), la seconde partie est axée sur lanalyse et la segmentation dimages (elle aussi en 2D ou 3D) afin den élever le contenu informationnel, la dernière partie porte sur les processeurs de traitement bas niveau.
2.2.1.1. Calibration de caméras et de télémètres
Cette étape est nécessaire quels que soient les capteurs utilisés, et plus encore dès linstant où leurs informations doivent être mises en commun. Elle permet dexprimer les informations issues de chaque capteur par rapport à un référentiel commun en vue de localiser dans un environnement des objets ou des obstacles. Les différents capteurs utilisés sont des caméras, utilisées seules ou en stéréovision, un télémètre laser IR à temps de vol, monté sur une tourelle orientable en site et en azimut ; un télémètre par triangulation utilisant une caméra fixe et un pointeur laser visible monté sur une tourelle orientable également en site et en azimut.
La calibration des caméras est effectuée à partir dune modélisation linéaire pour les focales supérieures à 10 mm. La détermination des paramètres du modèle de projection est alors obtenue par un algorithme de type filtrage de Kalman (introduit par Ayache (INRIA)), lui-même pouvant être initialisé par une approche linéaire du critère des moindres carrés utilisant une pseudo-inverse. La cible est représentée par des points lumineux de position connue au 1/10 de mm, la détection de leurs images peut être maintenant subpixellique (1/10 ème de pixel). Pour les objectifs à focale inférieure à 10 mm ou pour des objectifs de très faible coût, présentant des distorsions, nous avons modélisé celles-ci en tenant compte des distorsions radiales au premier ordre. La modélisation employée est celle introduite par Chaumette (IRISA) qui exprime les coordonnées pixels réelles en fonction des coordonnées linéaires et dun facteur de distorsion. Pour résoudre ce problème, nous avons appliqué une méthode doptimisation non-linéaire - Lenvenberg & Marquardt - qui permet de déterminer lensemble des paramètres (intrinsèques et extrinsèques) du modèle. Ces techniques sont maintenant bien connues de la communauté scientifique. Le laboratoire sest attaché à développer une expertise approfondie du domaine car une calibration correcte est la condition première à réaliser pour faire des relevés 3D de qualité. A partir danalyses de la robustesse, nous avons pu mettre en évidence que lorsque le modèle linéaire suffit, ce sont les paramètres globaux de projection qui sont les plus stables. Pour le modèle non linéaire, nous avons mis en évidence lintérêt du choix correct de la base dapprentissage, ainsi que lintérêt de disposer dune base de généralisation indépendante de la précédente pour déterminer la condition darrêt de lalgorithme [CHA98L]. Une procédure entièrement originale de calibration automatique robot/caméra qui permet de disposer de points de calibration dans tout lespace de travail du robot a été développée au laboratoire [MAL99C].
Ces travaux se poursuivent actuellement par la caractérisation d'une caméra munie d'un zoom montée sur une tête active [CHA98ST] et par la calibration dun capteur bi-oculaire faible coût à fortes distorsions destiné à une application de robotique domestique [LOA98C]. Nous avons testé lapport de techniques neuronales dans la calibration de caméra. Le modèle retenu a été celui des deux plans. La méthode développée est entièrement originale, elle permet de conduire lapprentissage du modèle inverse séparément sur chacun des plans.
Pour les télémètres temps de vol et par triangulation montés sur une tourelle à 2 degrés de liberté, nous avons défini, comme pour les caméras, un modèle interne (intrinsèque au dispositif de mesure) et un modèle externe caractérisant le situation du capteur par rapport au repère du monde. Comme ces modèles sont non linéaires, la méthode de calibration utilise, là aussi, un algorithme doptimisation non linéaire. La méthodologie de choix des points dapprentissage et de généralisation est la même que celle utilisée pour les caméras. Afin d'éviter toute ambiguïté de localisation des points 3D des diodes sensibles aux IR sont placées sur la mire de calibration [BARA97R], [BARA97C], [BARA98R].
2.2.1.2. Analyse dimages
a - Analyse dimages de textures
Depuis plusieurs années, des travaux de recherche portant sur lanalyse, la segmentation et lorientation de textures sont effectuées dans le groupe vision.
Intuitivement, la notion de texture nous paraît familière, mais en donner une définition précise devient plus complexe. Une texture est une information qui rend compte de létat de surface dun objet. Elle est caractérisée par larrangement plus ou moins régulier de motifs élémentaires. On distingue deux grandes classes de textures : les macrotextures, qui sont constituées par la répartition spatiale dun ou plusieurs motifs élémentaires nommés texels, et les microtextures qui ont un aspect aléatoire mais pour lesquelles limpression visuelle reste globalement homogène. Les textures donnent une information interne à une région. Dans des environnements flous ou perturbés, où linformation des contours nest pas une donnée fiable, posséder une description de lintérieur dune région est un atout important. Les méthodes classiques danalyse de textures sont très liées à la catégorie de textures à laquelle on sintéresse. Pour les macrotextures, on utilisera de préférence des méthodes structurelles, tandis que lanalyse des microtextures se fera souvent par des méthodes de type statistiques.
a1 - Approche multirésolution pour lanalyse des textures
Avant de concevoir une méthode générale pour la caractérisation de textures variées, nous nous sommes attaché à la connaissance du phénomène. Nous avons développé un générateur de textures nous permettant de simuler certaines situations et nous avons étudié les variations des paramètres fournis par les opérateurs classiques. Nous en avons déduit quune méthode unique nétait pas assez robuste face aux variations induites par le mouvement ou lorientation et nous avons décidé de construire un algorithme basé sur une combinaison de méthodes. La texture est un phénomène de type moyenne fréquence. Une analyse fréquentielle, assurée par une décomposition en ondelettes, couplée à une analyse statistiques réalisée par des opérateurs du type matrices de cooccurrences ou matrices de longueur de plages nous procure des résultats intéressants. La démarche développée est la suivante. Sur une image dune texture nous calculons un vecteur de cinq paramètres issus danalyse statistiques. Puis, nous décomposons limage en quatre sous-images de résolution inférieure selon le schéma donné sur la figure II.10. Les filtres h et g sont des filtres miroirs en quadrature monodimensionnels, lun de type passe-haut et lautre passe-bas. Ces quatre sous-images sobtiennent sans redondance dinformation.

Figure II.10 : Décomposition multirésolution dune image
Cette décomposition se poursuit à des échelles inférieures et nous réalisons ainsi une décomposition en paquets incomplets dondelettes. En effet, le choix de poursuivre ou non la décomposition dune sous-image est fait en fonction du contenu informationnel (au sens texture) de celle-ci. Sur chaque sous-image, à un niveau de décomposition donné, nous calculons le vecteur des cinq paramètres texturaux. Nous comparons ensuite ce vecteur à celui de limage de résolution supérieure en calculant une distance entre les deux vecteurs. Si la distance est grande, cela signifie que linformation contenue dans limage source est très peu présente dans cette sous-image, la décomposition peut donc sinterrompre. A linverse, si la distance est faible, cela induit que le contenu de cette sous-image est encore riche en information de type texture et quil est important de poursuivre la décomposition. La figure II.11 présente une image de texture (a) et le résultat de la décomposition obtenue (b).


(a) : texture originale 	 (b) : décomposition de 5(a)
Figure II.11
La méthode ainsi définie a été adaptée pour permettre daborder trois types de problèmes différents.
* La détection de défauts [LEL97C]
Dans le domaine industriel, et en particulier en contrôle qualité, de nombreuses applications nécessitent la recherche de défauts dans une surface qui nest pas homogène (textile, bois, agro-alimentaire,...). Linformation de texture, et la possibilité de déceler une rupture dans cette information, peut alors permettre la mise en évidence de ces défauts. Lintérêt de la démarche employée est quelle ne nécessite aucun apprentissage. Elle pourrait être complétée par une localisation des éventuels défauts.
* La classification de textures [ZAR97aC]
La classification de textures consiste à répondre à la question : " Est-ce que cet échantillon correspond à une texture connue ? " avec un taux de réussite important. Lapproche de décomposition arborescente nous a permis de proposer une solution à ce problème. La méthode utilisée présente un taux de classification correcte compris entre 90% et 100% selon les échantillons.
* La segmentation dimages multi-texturées [ZAR97bC]
Lutilisation la plus ambitieuse de notre approche combinée multirésolution et analyse statistique porte sur la segmentation dimages composées de plusieurs textures. Le principe du traitement est le suivant : limage à segmenter est décomposée de manière arborescente. On obtient donc un nombre, inconnu a priori, de feuilles qui ne sont pas toutes de la même taille. A partir dun nombre restreint de ces feuilles, on reconstruit les images caractéristiques qui sont de taille égale à limage initiale. Avant daborder la phase de classification des pixels, les images caractéristiques sont lissées, puis on effectue une étape de réduction de la dimension de lespace de représentation en utilisant une transformation de Karhunen-Loeve. La classification, cest-à-dire laffectation de chaque pixel de limage à une région de limage présentant une caractéristique jugée homogène (ici la texture), est réalisée par une méthode de type "nuées dynamiques". La figure II.12 présente un exemple dimages comportant cinq textures (a) et le résultat de la segmentation obtenu par notre algorithme (b).
Poursuite de ce travail
Suite au départ de Rachid ZARITA, ce travail sest poursuivi à travers deux stages, lun dingénieur-maître [DAS99S] et lautre de DESS [MON00S], dans loptique de rendre opérationnel le travail déjà réalisé et de permettre une phase exhaustive de test. Actuellement nous envisageons dutiliser ces algorithmes comme base à un travail sur les méthodes de classification. Le principe consisterait à remplacer la partie du programme qui utilise la méthode des nuées dynamiques par dautres méthodes de classification, en particulier basées sur les algorithmes de type KPPV, logique floue, neuronaux, et de comparer les résultats auxquels nous conduisent ces différentes approches. Cette recherche permettrait en outre une action transversale entre la composante vision et la composante classification/analyse de données. Un sujet de stage de DEA est dailleurs proposé dans ce sens.


(a) : image originale avec 5 textures (b) : résultat de la segmentation de 6(a)
Figure II.6
a2 - Reconnaissance de lorientation de surfaces texturées
Le travail décrit ici est le fruit dune collaboration entre le Département de Sciences Cognitives et Ergonomie de lIMASSA à Brétigny et le CEMIF-LSC. Le but est de construire un système daide à la reconnaissances de formes dans des images de scènes naturelles. Les formes impliquées ne sont pas forcément de couleur ou de surface uniforme. Il faut donc être capable de reconnaître différentes faces dun objet qui peuvent être vues sous différentes orientations de manière à les apparier ou bien de segmenter des formes qui auraient été attribuées indûment au même objet. Dans un premier temps, ce travail a porté sur une méthode permettant de séparer de microtextures des macrotextures [BOU97S]. En effet, les calculs dorientation qui seront faits ne seront pas les mêmes dans les deux cas [BOU97C]. Ce travail sest continué par une thèse portant sur le calcul de lorientation de surfaces planes texturées. Les textures utilisées dans ces hypothèses sont des macrotextures plus ou moins régulières. En effet lors de la projection sur un plan, une texture subit trois types de déformations comme lillustre la figure II.7 :
Une étude bibliographique sur les méthodes de " Shape From Textures " (SFT) a montré que les techniques permettant de recouvrir lorientation du plan pouvaient utiliser un ou plusieurs de ces trois effets. Pour notre part nous avons opté pour une méthode basée sur le calcul de la carte des fréquences locales. En effet la fréquence locale est affectée par les 3 types de déformations que nous venons de citer. Cette information est donc à même de nous permettre de remonter aux paramètres de lorientation du plan avec le maximum de précision.
Extraction des fréquences locales :
Dans cette étape nous avons développé une méthode originale basée sur une décomposition en ondelettes par des fonctions du type " Différence de gaussiennes (DOG ". Nous utilisons des ondelettes en contraste de manière à sabstraire au maximum des variations de luminance locales de limage. Les échelles des ondelettes retenues sont des multiples de racine de 2 et varient de 1 à 128 pour des images de taille 256x256. Pour chaque pixel de limage nous obtenons donc 15 valeurs, correspondant chacune à la réponse dune des ondelettes. La valeur affectée in fine à ce pixel est une valeur donnant le maximum de toutes les réponses, après interpolation de cette courbe [BOU99C]. Cette valeur que nous appelons " échelle locale " est en fait linverse de la fréquence locale. La figure II.8(b) présente la carte des échelles locales obtenues à partir de la figure II.8(a).
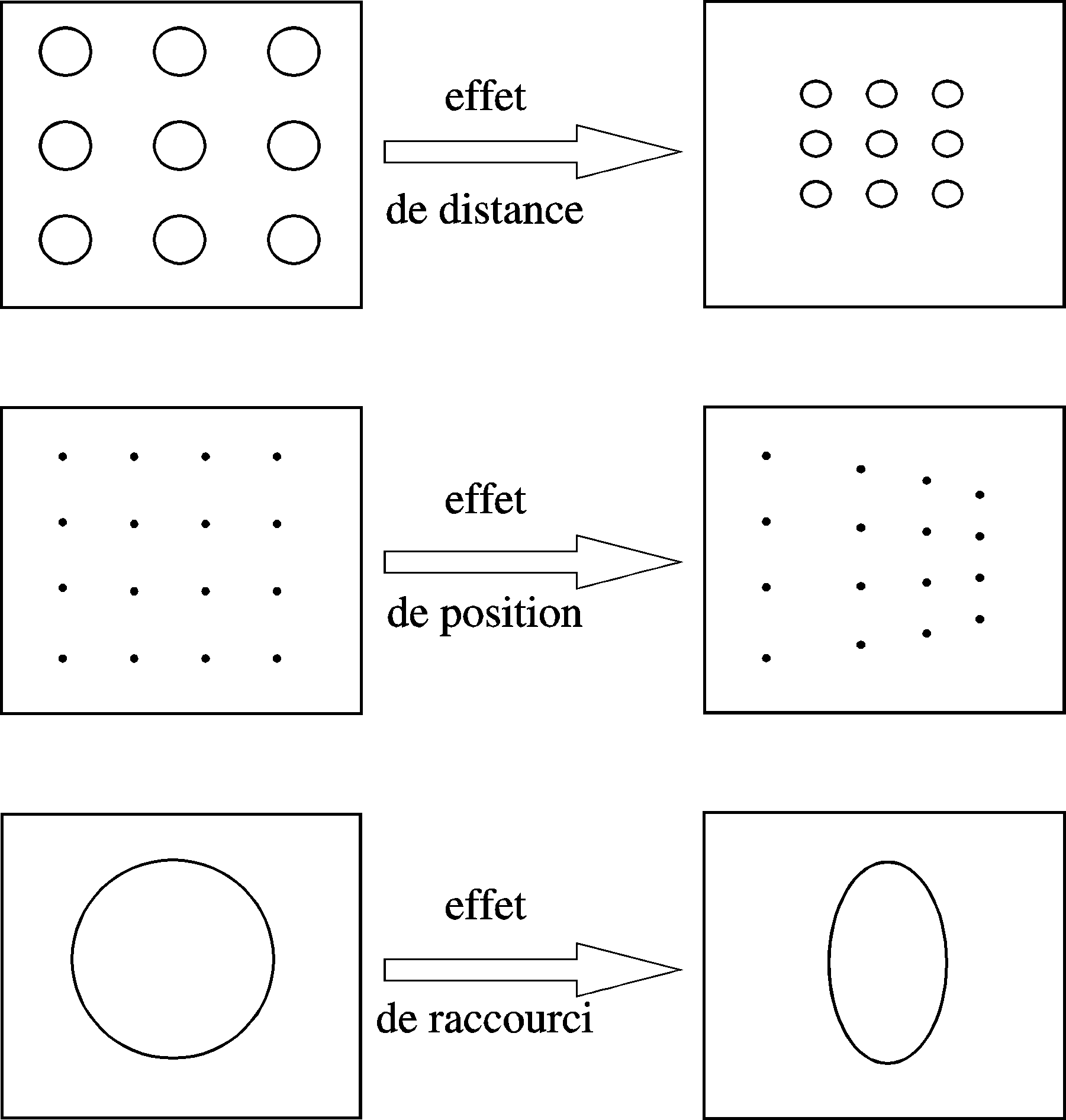
Figure II-7 : Les trois types de déformation subies par une texture projetée


(a) image originale (b) carte de échelles locales de (a)
Figure II-8
Calcul de lorientation :
Le modèle le plus couramment retenu pour décrire lorientation du plan dans les méthodes de SFT est un modèle basé sur deux angles :
Ces deux angles sont illustrés sur la figure II.9.
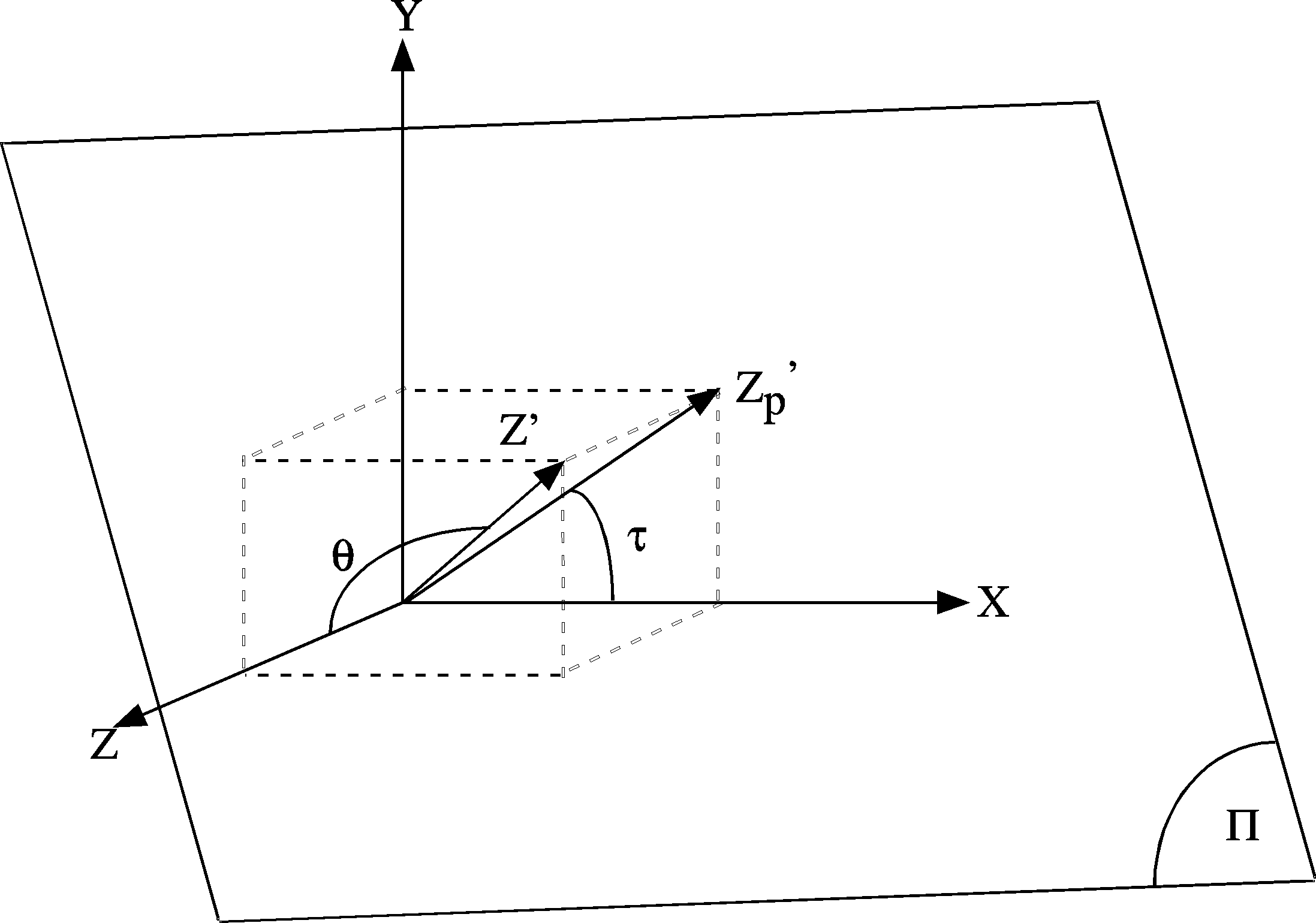
Figure II-9 : Représentation par les angles de tilt et de slant
Le calcul de ces deux angles est basé sur une amélioration de la méthode de LU et al.. Pour effectuer ces calculs, il faut faire une interpolation de la courbe théorique de la carte des échelles locales de limage. La courbe à interpoler nest pas un polynôme du second degré général, comme on pourrait le penser de prime abord, mais un paraboloïde orienté selon la direction du tilt. Cette restriction de la famille des polynômes du second degré pose un problème dinterpolation que nous avons résolu. Outre les améliorations de la méthode de LU et al., loriginalité de ce travail réside dans une étude approfondie de la précision que lon peut attendre des méthodes de SFT. Nous avons pu montrer, par des expérimentations sur des images de synthèse, que si la précision sur langle de tilt pouvait être excellente, de lordre du degré, il nen allait pas de même pour langle de slant. En particulier, nous avons pu montrer que pour des valeurs de q inférieures à 30°, limprécision pouvait atteindre une vingtaine de degrés. Ces méthodes paraissent donc intéressantes pour des surfaces inclinées dun angle q > 40°. Des calculs théoriques des erreurs nous ont permis de mettre en évidence limportance de la calibration de la caméra lors de la prise de vue de telles images. En effet, une erreur peu importante sur la focale ou sur la position du centre optique, aura une répercussion importante sur les angles tilt et de slant. En particulier, ces erreurs seront maximums pour des valeurs de q de lordre de 40° (cest à dire là où on peut espérer une précision correcte des méthodes de SFT).
Expérimentation sur des images réelles :
Pour valider le travail théorique que nous venons de présenter rapidement, une base de données dune centaine dimages a été constituée. Ces images sont réalisées à partir dune douzaine de macrotextures différentes, orientées selon des angles de tilt et de slant variables. La caméra ayant servie à la numérisation a été préalablement calibrée et la distorsion a ainsi pu être corrigée. A partir de ces images, nous avons pu valider lintérêt des améliorations apportées à la méthode de LU et al. pour le calcul de langle de slant. Ces améliorations sont significatives, tant au niveau de la précision que de la stabilité des résultats.
Applications de cette méthode de SFT :
Pour finir, trois prolongements de lutilisation dune telle méthode de SFT ont pu être mis en évidence. Le premier consiste en une extraction des texels présents dans la texture. En effet, lors de la projection de la texture sur le plan incliné, les texels éloignés du centre optique de la caméra sont resserrés entre eux, et les niveaux de gris de ces texels se trouvent affectés. Un seuillage global de limage nest pas possible, et nous avons développé une méthode utilisant les paramètres de linterpolation afin de fixer une valeur de seuil pour chaque pixel de limage [BOU00C]. Ces texels extraits, il est possible pour des textures présentant une structure régulière, de modéliser lorganisation des texels en utilisant une triangulation de Delaunay. A partir de cette grille, on peut envisager une détection de défauts. En effet les défauts de la texture vont venir rompre la régularité de la grille et pourront donc être mis en évidence. La dernière application permet de confirmer la valeur de langle de slant en calculant la ligne de fuite à partir des droites constituant la grille obtenue. Un test sur une trentaine dimage a montré que lerreur commise sur q était diminuée dune dizaine de degrés.
Lensemble de ce travail a été présenté lors de la soutenance de thèse de Laurent BOUTTE [BOU00T]. Plusieurs articles sont en cours pour faire connaître les résultats de cette étude. La collaboration scientifique avec lIMASSA devrait se continuer autour de ce sujet ou sur des problèmes danalyse multirésolution dobjets présents dans une scène complexe. Deux sujets de DEA ont été proposés dans ce sens.
c Analyse dimages biomédicales
Dans le cadre de la recherche en génétique, qui est un des axes de recherche prioritaire de lUniversité dEvry Val dEssonne, une équipe de recherche en bio-informatique a vu le jour. Un DEA de bio-informatique a également démarré en octobre 2000. Nous avons initié une collaboration avec cette équipe. Après la participation à des séminaires et la présentation dun exposé sur les outils de base du traitement des images à un de ces séminaires, cette collaboration devrait se matérialiser par lencadrement commun dun DEA, dont le sujet porte sur lanalyse des images de puces dADN.
d - Processeurs spécialisés pour limagerie bas-niveau
Ces travaux comprennent essentiellement les recherches effectuées par D.Hanifi dans le cadre de la préparation de son doctorat sous la direction de M. SHAWKY. Ce dernier ayant quitté le CEMIF en septembre 1997, ces travaux nont pas perdurés au-delà de la soutenance de la thèse [HAN99T]. Le thème principal de ces recherches est : " Intégration du traitement bas niveau au capteur visuel (caméra) ".
Le travail effectué porte d'une part sur l'implantation matérielle du traitement dit de bas niveau et, dautre part, il a pour but de remonter la barrière bas-haut niveau en intégrant également à l'implantation des fonctions plus élaborées telle que l'étiquetage des points de contour. Les autres points développés au cours de cette thèse sont les suivants :
- développement d'une passerelle d'un langage orienté traitement d'images, notamment APPLY, vers le VHDL ou des hard-macros afin d'obtenir une architecture facilement programmable par un non-expert en électronique,
- élaboration d'une bibliothèque de fonctions matérielles de base pour le traitement d'images,
Plusieurs publications dans des conférences et des revues ont été réalisées sur ce sujet : [HAN98C], [SHA98C] et [SHA98R].
2.2.2. Modélisation et reconstruction denvironnements 3D
La reconnaissance d'objets 3D nécessite la modélisation 3D de ceux-ci pour les incorporer dans une base de données 3D, la reconstruction 3D afin de calculer leur nouvelle situation en cas de mouvement de ceux-ci et l'appariement 2D/3D afin de réaliser une reconnaissance automatique. Nous présentons les méthodes que nous avons développées pour modéliser, reconstruire et apparier les objets 3D avec leur image 2D.
2.2.2.1. Modélisation 3D
Dans cette partie, des méthodes de modélisation de volumes englobants dobjets polyédriques et cylindriques, présentant une symétrie, ont été élaborés en utilisant une caméra et un télémètre monté sur un dispositif rotatif à deux degrés de liberté. Cette modélisation est utilisée pour enrichir la base de données 3D de lenvironnement afin de permettre la réalisation de tâches robotiques. Elle nest en aucun cas destinée à modéliser fidèlement des objets de formes complexes. Cette modélisation est réalisée interactivement avec la coopération de lutilisateur qui indique la classe dobjet à modéliser et télécommande les capteurs afin de réaliser le relevé 3D, nécessaire au calcul des dimensions et lattitude spatiale de lobjet.
Trois classes dobjets sont considérées : celle des prismes symétriques, celle des cylindres et celle des objets à symétrie de révolution n'appartenant pas aux deux catégories précédentes et à génératrice non forcément rectiligne.
L'idée originale pour toutes ces méthodes consiste à utiliser le capteur mixte constitué par la caméra et le télémètre. Limage caméra sert à positionner l'objet dans une pyramide infinie ayant pour sommet le centre optique de la caméra. Le télémètre fournit l'information de profondeur qui permet de situer lobjet dans la pyramide(Thèse de E.C. Nzi, 1995).
Par ailleurs, Deux méthodes de calcul du graphe daspects, nécessaire à l'appariement 2D/3D, ont été développées. L'une géométrique et l'autre analytique[SHA00T].
La méthode géométrique a été développée pour servir à l'appariement basée sur le hachage géométrique, utilisant les sommets du modèle 3D. Un aspect est alors représenté par un ensemble de sommets visibles simultanément.
On considère une sphère de gauss centrée sur lobjet que lon discrétise selon les longitude et latitude pour obtenir une série de points repartis sur la surface de cette sphère. Un point P représente ainsi un point de vue adopté pour projeter le modèle.
Cette méthode a le mérite dêtre rapide et de fournir un graphe correspondant uniquement à ce que lobservateur peut voir. De plus elle sapplique à nimporte quel type de polyèdre immédiatement avec la même complexité algorithmique. Cependant le graphe daspects est généralement incomplet et sa précision de celle de la discrétisation et du rayon de la sphère.
La méthode analytique a été développée pour servir à l'appariement basé sur un graphe. Elle fournit le graphe complet d'un objet polyédrique. Le problème a été abordé en deux étapes de complexité croissante ; il sagissait tout dabord de traiter les polyèdres convexes, puis de sétendre au cas général en incluant les polyèdres concaves. Afin dobtenir lensemble des aspects dun polyèdre, un graphe dincidence est crée.
Le graphe dincidence (GI) est la représentation dune parcellisation de lespace. Pour le construire, la liste des plans support des faces de lobjet est calculée. Lintersection entre trois plans, supports de faces de l'objet, constitue le noyau du graphe dincidence. A chaque itération, un nouveau plan de la liste subdivisera les plans antérieurs. En exploitant toute la liste des plans, le graphe dincidence est entièrement construit. Chaque cellule du graphe représente une parcelle de lespace, contenant tous les points de vue à partir desquels on voit toujours le même aspect du polyèdre. Un codage est attribué à la cellule. Celui-ci est représenté par n bits où n est le nombre de faces du polyèdre. Létat dun bit définit la visibilité dune face. Une face nest considérée visible, dun point de vue donné, que si ce celui-ci est situé du bon côté du plan support de la face, cest à dire du côté où se trouve la normale à la face(la normale à une face est orientée vers l'extérieur de la matière).
Les feuilles du GI représentent les différents aspects, les nuds constituent les codages intermédiaires et les arcs les évènements visuels représentant le passage dun aspect à un autre.
La parcellisation de lespace est complétée pour le cas concave en ajoutant celle obtenue par des plans auxiliaires. Ceux-ci sont issues des événements visuels de type segment/point [SHA00T].
2.2.2.2. Reconstruction 3D
La reconstruction 3D consiste à réactualiser la base de données 3D de lenvironnement en se basant uniquement sur les indices 2D fournis par limage caméra. Lapproche utilisée consiste à déterminer la transformation rigide (rotation et translation) subie par lobjet dont la géométrie est à priori connue.
La méthode utilisée se déroule en deux étapes. Dans la première étape, on utilise une méthode géométrique valable quel que soit langle de rotation, basée sur la connaissance de trois arêtes L1, L2, L3 du modèle d'un objet, défini dans un système d'axes (Rm) lié au modèle, et de trois segments l1, l2, l3 détectés dans une image et définis dans le système d'axes (Rc) lié à la caméra. L'objectif est de déterminer la rotation R et la translation T à appliquer à Li (i=1..3) afin que leurs images coïncident avec celles des li. Nous avons adapté la méthode développée par M. Dhome (LASMEA) en proposant un formalisme plus direct.
Lobjectif de la seconde étape est daffiner le recalage à grande amplitude à laide dune méthode de reconstruction appliquée aux petites rotations. Dans ce cas, il est possible de linéariser le système à résoudre, ceci présente le grand avantage de pouvoir utiliser des informations redondantes et ainsi de délivrer un résultat plus précis. Les paramètres trouvés par cette méthode sont les coordonnées du vecteur translation et du vecteur rotation instantanée [NZI97R].
Une autre approche a été testée. Elle est basée sur la connaissance des distances entre certains sommets de lobjet à reconstruire. L'idée est de positionner directement dans l'espace 3D les points qui définissent les sommets de l'objet à reconstruire. Ces points sont situés sur une droite connue (le rayon optique associé à ce point) et le principe de la méthode consiste à définir la distance entre le point recherché et un point arbitraire du rayon optique qui peut être le centre optique. Les paramètres de la rotation et de la translation sont déterminés alors par un algorithme doptimisation non linéaire [MOR97C].
Un algorithme de recalage mixte, utilisant trois méthodes : la méthode analytique décrite, ci-dessus, et deux méthodes numériques l'une non linéaire(valable quelque soit l'amplitude du mouvement de l'objet) et l'autre linéaire (valable pour un mouvement de faible amplitude). L'idée de ce mixage est de pallier le cas où l'application de la méthode analytique suivie de la méthode linéaire ne donne pas de résultat. Dans ce cas, la méthode de Levenberg-Marquart est appliquée pour tenter de trouver une solution. L'application de cet algorithme donne un résultat plus robuste et plus précis, [SHA01R].
Nous poursuivons nos recherches sur le recalage 3D appliqué à des objets présentant des faces gauches, dans le cadre de la thèse de F. Ababsa, encadré par Malik Mallem et David Roussel. Nous envisageons de mettre à contribution les informations issues d'une caméra vidéo-et d'une source lumineuse afin de restituer l'attitude d'un objet de forme libre connu à priori.
2.2.2.3. Appariement 2D/3D
Pour appliquer les méthodes de recalage décrites précédemment, il est nécessaire dapparier les indices 2D extraits de limage comportant lobjet avec les primitives correspondantes de son modèle 3D.
Les méthodes dappariement étudiées au laboratoire sont applicables aux objets polyédriques.
La transformée de Hough est appliquée pour la segmentation de l'image. L'élaboration du modèle 2D est basée sur l'organisation perceptive des indices 2D extraits de l'image.
Le modèle 3D est de type B-Rep (" Boundary Representation "), un graphe d'aspects, valable pour des objets polyédriques convexes et concaves, qui décrit la topologie du modèle 3D est créé automatiquement, il est représenté par l'ensemble des vues d'un objet. Nous nous limitons aux aspects dits topologiquement différents, cest-à-dire des aspects dont les éléments géométriques visibles sont différents.
Dans la méthode du graphe dappariement, un graphe de compatibilité entre le modèle 2D et le graphe d'aspects est élaboré. Les arcs du graphe de compatibilité représentent les hypothèses d'appariement entre une chaîne de segments 2D et une face d'un aspect du modèle 3D. Ensuite, la transformation précise entre le modèle 3D et le repère de l'environnement est calculée dans la phase de vérification durant laquelle on applique les invariants géométriques, basés sur des rapports de surfaces de l'objet dans le modèle 3D et dans l'image 2D, pour éliminer les hypothèses invalides (figure II.11). Ceci constitue loriginalité forte apportée par le laboratoire dans cette méthode [SHA00S].
Cette méthode est tributaire de la qualité de l'image caméra. Si celle-ci est dégradée, le résultat du traitement de l'image s'avère insuffisant - difficulté d'extraction des chaînes de segments - pour appliquer la méthode du graphe dappariement. Ce problème est traité en utilisant une méthode de hachage géométrique basée sur les sommets des objets [SHA99T].
Toutes les méthodes décrites sont validées en utilisant le banc d'expérimentation représenté sur la figureII.12.
Figure II.11: Le modèle de l'objet Pince est superposé sur son image avec erreur moyenne de 2.6 pixels, les hypothèses chaîne/face sont marquées
2.2.3. Travaux en vision réalisés dans le cadre du LCTRV (Laboratoire Commun de Téléopération et Réalité Virtuelle)
Depuis juin 1999, une collaboration implique le CEMIF dans les activités de recherche du LCTRV. Le LCTRV est un laboratoire qui mène des activités sur les thèmes de la téléopération, de la robotique et de la réalité virtuelle. Ce laboratoire a été créé en janvier 1999 pour rassembler sur ces thèmes les ressources de R&D du Centre d'Etudes Mécaniques d'Ile de France (CEMIF) de l'Université d'Evry Val d'Essonne, du Laboratoire de Robotique de Paris (LRP) de l'Université de Versailles St Quentin et du Service de Téléopération et de Robotique (STR) du Commissariat à l'Energie Atomique de Fontenay-Aux-Roses, où est localisé le LCTRV et qui est structuré de la façon suivante : Raymond FOURNIER (CEA / STR) -- coordinateur , Alain MICAELLI (CEA / STR), Philippe COIFFET (UVSQ / LRP), Florent CHAVAND (UEVE / CEMIF) -- responsables scientifiques.

Figure II.12: Banc d'expérimentation
Le principal objectif du LCTRV est de développer de nouveaux outils et méthodes dans le domaine de l'interaction homme-machine (Interfaces Haptiques, Rendus Haptiques, Téléprésence et Présence). Les domaines d'applications sont pour la plus grande part professionnels comme la maintenance téléopérée, le prototypage virtuel pour la simulation de montage / démontage et la maintenance, la formation sur simulateur et le médical avec une activité déjà ancienne (1977) sur l'assistance aux handicapés (réalisation de la base fixe téléopérée MASTER) et une activité plus récente (1996) sur l'assistance au geste chirurgical.
Paul CHECCHIN (Maître de Conférences) intervient plus particulièrement dans le cadre des projets visant à l'utilisation de la vision artificielle pour l'assistance à la téléopération. Il travaille en collaboration de M. Rodolphe GELIN du CEA est le chef du projet et Mlle Anne MALAVAUD, ingénieur au CEA. L'objectif de l'action est d'utiliser la vision pour améliorer l'efficacité des systèmes de téléopération développés par le CEA.
Deux voies ont été retenues, la première est la mise au point d'un procédé sans contact permettant de déterminer la normale à une surface pour aider un opérateur de télémanipulateur à positionner correctement un outil avant l'exécution de la tâche. La seconde consiste à utiliser la vision pour obtenir une calibration géométrique du robot.
2.2.3.1. Détermination de la normale à un plan par un procédé sans contact.
Ce travail consiste à poursuivre les développements faits en 1999 sur la mise en oeuvre d'un capteur stéréoscopique actif composé d'un projecteur laser et d'une caméra CCD couplés rigidement. Le projecteur laser utilisé est un Lasiris SNF 5x5L 670-20. Il projette une grille laser carrée. La solution adoptée pour recouvrer l'information orientation et 3D est fondée sur l'exploitation des méthodes de vision stéréoscopique, en particulier la géométrie épipolaire. Cette contrainte épipolaire est représentée algébriquement par la matrice fondamentale, matrice qui doit être estimée de manière rigoureuse à l'aide d'outils numériques mettant en oeuvre des techniques d'optimisations non-linéaires.
Les développements récents ont consisté à améliorer la robustesse du procédé vis-à-vis de conditions d'opération. En effet, la solution initiale nécessitait une intervention de l'opérateur pour apparier le motif projeté à son modèle et elle ne fonctionnait pas quand tous les indices du modèle n'étaient détectés dans l'image. De nets progrès ont été obtenus en utilisant la contrainte épipolaire.
Le calcul de la normale passe par plusieurs étapes principales. La première est la calibration du capteur stéréoscopique. La deuxième consiste en la détection subpixelique des centres des croix correspondant aux intersections des lignes verticales et horizontales de la grille projetée. La troisième étape vise à apparier les points détectés dans le plan image de la caméra et leur antécédent sur la grille du projecteur laser. Enfin, une dernière étape permet de calculer aussi bien de trouver les coordonnées 3D des points et/ou l'orientation du plan. Pour cette dernière étape, plusieurs solutions ont été implémentées dont une mettant en oeuvre l'estimation de l'homographie entre le plan image de la caméra et le plan image du projecteur.
2.2.3.2. Calibration d'une caméra embarquée sur un bras robotisé
L'expérience montre que la mise en oeuvre d'une caméra embarquée sur un bras robotisé est rendue délicate par le besoin de disposer d'une caméra parfaitement calibrée (identification des paramètres intrinsèques et extrinsèques). Or celle-ci ne peut plus être installée sur un banc de calibration. Les développements actuels menés portent sur une méthode de calibration simplifiée pouvant être réalisée alors que le robot et la caméra ont déjà été introduits sur un site hostile. La méthode consiste à prendre une dizaine de prises de vues d'une mire connue qui aura été introduite sur le même site que le robot. Grâce à l'algorithme de DEMENTHON, la position de la caméra vis à vis de la mire est calculée. On dispose alors de toutes les informations nécessaires pour alimenter un algorithme d'optimisation qui identifiera les meilleures valeurs des paramètres intrinsèques et extrinsèques de la caméra.
Les algorithmes de vision, notamment ceux développés dans l'activité précédente, fournissent des informations géométriques exprimées dans un repère lié à la caméra. Pour que le robot puisse les interpréter, il est nécessaire de connaître la transformation géométrique qui permet de passer du repère caméra à un repère lié au robot. Pour identifier cette transformation, il faut connaître la position de la caméra sur le bras. La méthode qui va être utilisée est l'application du logiciel GECARO (Calibration Géométrique de Robot de l'ECN). L'étude est en cours sur un robot dont le modèle géométrique est parfaitement connu (le RX90).
Ces travaux ont donné lieu à une activité d'encadrement :
- Benjamin VINCENT, agrégé de l'ENS Cachan, stagiaire du DEA Robotique de l'Université Pierre et Marie Curie (Juin 2000) au LCTRV su CEA de Fontenay-Aux-Roses (92) sur le sujet :
Calibration de caméra et étalonnage bras-oeil (co-encadrement avec Mlle Anne MALAVAUD, ingénieur CEA)
- Francis NGUYEN, élève ingénieur IIE, stagiaire (janvier à juin 2000 au LCTRV su CEA de Fontenay-Aux-Roses (92) sur le sujet :
Acquisition de données 3D par un capteur stéréoscopique actif : assistance à la téléopération (co-encadrement avec Mlle Anne MALAVAUD, ingénieur CEA).
- Aymeric NOIZET, élève ingénieur IIE deuxième année, stagiaire (juin à août 2000) au LCTRV su CEA de Fontenay-Aux-Roses (92) sur le sujet :
Etude et réalisation d'un capteur de perception surfacique tridimensionnelle sans contact par projection de grille laser (co-encadrement avec Mlle Anne MALAVAUD, ingénieur CEA).
2.2.4. Applications vision
Les travaux précédents sont ou ont été appliqués à divers projets en collaboration avec différents partenaires :
Un capteur peut être défini selon les deux points de vue, fonctionnel et technologique :
* Point de vue fonctionnel
Les capteurs intelligents sont des dispositifs capables de détecter, de mesurer, de traduire, de dater et de traiter les données collectées en vue de les communiquer à d'autres organes du système dans lequel ils sont intégrés.
* Point de vue technologique
Le capteur intelligent correspond principalement à l'intégration, dans le corps du capteur, d'un organe de calcul interne (microprocesseur, micro-contrôleur, DSP), d'un système de conditionnement du signal (programmable ou contrôlé) et d'une interface de communication.
Nous nous sommes intéressés, dans le cadre de la télémétrie laser ou ultrasonore et de la vision., à laspect fonctionnel en proposant des méthodes de prétraitement et de traitement des données et à laspect technologique en définissant et réalisant les organes de traitement et de communication. La représentation de laspect fonctionnel sappuie sur un modèle de type client serveur qui fait apparaître à la fois la notion de service et de hiérarchie. Le passage au service de niveau supérieur se traduit par une élévation du degré sémantique de linformation.
Les applications robotiques requierent un système de perception capable de sadapter aux besoins de la tâche en cours. Les différents modes dutilisation apparaissent comme des sous-ensembles de lensemble des services (Figure II.13)
Figure II.13 : Modes dutilisation et services
2.3.1 La fonction traitement de données
Dans cette partie, sont présentées trois études originales menées au laboratoire. Lune porte sur la correction de leffet dempreinte dun télémètre laser réalisée à partir de linversion du modèle physique du capteur. La deuxième concerne la conception dun nouveau capteur multiaural, multimode. Ces deux études présentent dans les méthodes employées de grandes originalités. La troisième est en cours, elle concerne la conception dun capteur bi-oculaire multimode.
2.3.1.1. Correction de leffet dempreinte dun télémètre laser
La modélisation d'un capteur consiste à définir un modèle puis à développer des méthodes d'identification des paramètres et d'évaluation du modèle obtenu. Suivant le point de vue qui dépend des objectif à atteindre, un capteur sera représenté par un modèle différent : un modèle géométrique dont la calibration a été abordée au §2.1.1.1, et un modèle géométrique qui fait lobjet de cette présentation. Dans le cadre de la télémétrie laser, nous nous sommes intéressés à un télémètre monté sur une tourelle orientable en site et azimut.
Le modèle physique tient compte du procédé de mesure (par exemple, diamètre du faisceau du télémètre laser). En fait, on peut considérer le modèle physique direct et le modèle physique inverse [BARA97T].
Le modèle direct est représenté par un modèle non-linéaire identifié en suivant une approche d'automatique classique. Ce modèle sert principalement à la création de profiles simulés utiles au développement du modèle physique inverse.
Le modèle physique inverse permet de corriger l'effet d'empreinte, effet provenant de la tâche de mesure qui n'est pas ponctuelle. Cet effet limite la résolution angulaire et bien que noté dans différents travaux n'est généralement pas corrigé.
Une approche mixte pour représenter le modèle physique inverse est utilisée. Elle se compose d'une classification des profils mesurés à l'aide de réseaux de neurones et d'une correction des profils mesurés par une méthode paramétrique. Le modèle physique inverse est intégré dans les deux applications et son apport a été évalué dans deux domaines dapplication. En robotique mobile, il permet un meilleur recalage d'un robot mobile dans un environnement connu ou partiellement connu [LEC98ST]. En téléopération, il améliore l'information de profondeur présentée à l'opérateur sous la forme d'une image synthétique superposée à l'image caméra
Le modèle, de part sa structure modulaire, est adaptable aisément à de nouveaux télémètres laser. Les techniques de traitement de données sont aisément transposables à d autres domaines dapplications. Par exemple, une approche neuronale a été appliquée à la reconnaissance de portes considérées comme des amers dans le cadre du projet AFM [HOP99R].
2.3.1.2. Vers un système ultrasonore multimodal et multiaural
Dans le cadre de la télémétrie ultrasonore [HAM98T], les objectifs de cette recherche visent à améliorer les caractéristiques métrologiques du capteur et à obtenir une information plus complète que la simple distance capteur/cible, comme la forme des éléments de lenvironnement visés par le capteur. Ces travaux suivent trois directions : mieux exploiter l'information contenue dans l'onde réfléchie (forme, durée, amplitude), améliorer la précision de la mesure par des techniques issues du traitement de signal, définir un système multicapteur multimodal ultrasonore pouvant répondre à différentes tâches, proximétrie, télémétrie , reconnaissance de formes.
Afin de mieux comprendre les limites et les avantages dun capteur ultrasonore, un modèle direct a été élaboré. Lapproche considère le système capteur-environnement comme un seul processus. Grâce à la formulation de Barshan et Kuc, basée sur la réponse impulsionnelle, le système capteur-environnement est vu comme un seul processus et les effets du capteur peuvent être partiellement découplés de ceux de lenvironnement. Les mesures expérimentales ont montré quun filtre passe bande dordre 3 et centré sur 50 kHz est suffisant pour décrire le comportement du capteur. Pour modéliser lenvironnement, on sest intéressé uniquement à lamplitude du signal réfléchi par la cible en supposant que lenvironnement est constitué de surface lisse relativement à la longueur donde des ultrasons. Cette première étape a permis de dégager les potentialités des capteurs ultrasonores et de disposer dun simulateur capable de fournir le signal renvoyé par différentes cibles.
Lobjectif suivant a été de retrouver le profil réel à partir dun profil mesuré obtenu par balayage de lenvironnement. La recherche du modèle inverse a été ramené à un problème de classification [LIP97ST]. Le classifieur est construit autour dun réseau de neurones capable de distinguer quatre formes différentes : le plan/coin, larête, le cylindre et la tige. Les entrées sont n mesures damplitude successives du signal écho et le temps de vol. Les résultats expérimentaux donnent un taux de réussite de lordre de 86%. Pour permettre à ce système de traiter un nombre dentrées variables fonction du nombre dimpact sur une cible donnée, un prétraitement est effectué avant le RN décrit précédemment. Son rôle est de compléter le vecteur de mesure par une technique de quantification vectorielle. Cette approche suppose que linformation contenue dans le vecteur de mesure est suffisante pour la classification. Un dernier module de décision, comprenant une sortie rejet, est ajouté en sortie du classifieur neuronal afin dadapter la décision finale aux contraintes de lapplication (sortie optimiste ou pessimiste). Les travaux en cours ont comme objectifs la définition (terminée) et la réalisation dun dispositif ultrasonore multiaural et multimodal en intégrant les différentes approches selon deux axes. Le premier concerne lamélioration des caractéristiques métrologiques :
Le deuxième axe sintéresse aux différents modes de fonctionnement du dispositif pour répondre aux tâches attendues, mesures précises, reconnaissance denvironnement,...
Plusieurs aspects abordés précédemment restent à développer. On peut citer principalement le développement de la méthode de quantification vectorielle et létude de lenveloppe du signal reçu comme information pertinente pour la classification de cible en environnement complexes ou encore lintérêt du multiécho [DOI98ST].
Le travail concernant la classification de mesures ultrasonores se poursuit actuellement par une thèse qui a débuté en Novembre 1999 (directeur de thèse Professeur E. Colle et encadrement C. Barat). Le titre de la thèse est Perception intelligente à partir de capteurs frustres pour la robotique de service. Lobjectif est de mettre à disposition de la robotique de service des systèmes de perception de lenvironnement peu onéreux construits à partir de capteurs frustres (information imprécise et incertaine). On se limitera aux capteurs actifs qui fonctionnent par émission dénergie et détection de lénergie renvoyée par des cibles (exemples : télémétrie ultrasonore et laser, radar, camera active,etc.).
Le terme intelligent sous entend la capacité du système de perception à modifier son comportement en fonction de certains facteurs généralement externes. Lidée est dimiter le fonctionnement de la chauve-souris qui analyse les signaux réfléchis et adapte son signal démission en fonction de la mission (recherche, identification, poursuite).
2.3.1.3. Capteur bi-oculaire multi-modal
Ce capteur est destiné à équiper un robot mobile. Sa configuration stéréoscopique est originale puisque les deux caméras qui léquipent sont placées dans une configuration verticale (figure II-14). Lune regarde lhorizon tandis que la seconde est dirigée vers le sol. La configuration de ces capteurs permet cependant davoir des champs de vision qui se recouvrent afin de pouvoir apparier des indices visuels communs [LOA98cC].

Figure II-14 : Tête stéréoscopique avec les deux caméras.
De plus ces caméras sont montées sur une tourelle orientable en azimut permettant deffectuer un balayage à pas continu de lenvironnement du robot mobile. Dans ces conditions, le système de vision permet de réaliser des mesures tridimensionnelles en utilisant trois modes possibles [LOA99aR] :

Figure II-15 : Le robot mobile et les deux vues issues du capteur montrant la mire de calibration.
Un autre point important à propos de ce capteur concerne la qualité très médiocre des caméras employées. Ceci nous a permis de tester des algorithmes dans un cas de vision fortement dégradée. Après avoir défini la géométrie du capteur, il a fallu le caractériser. Pour cela une comparaison a été faite entre une caméra standard et une des caméras du capteur stéréoscopique. Cette étude a mis en évidence les problèmes de distorsion et de dynamique présentés par cette caméra [LOA99bC].
Une fois le capteur connu, le travail a porté sur les traitements nécessaires pour passer de linformation image à linformation segments. En effet, le but de ce travail étant de proposer un capteur de localisation et de navigation pour un robot mobile, il faut pouvoir se situer dans lenvironnement 3D. Le choix que nous avons fait pour atteindre ce but est dapparier des segments extraits des deux images. Les traitements réalisés [LOA98aS] sont donc les suivants :
Les résultats de ce traitement des images sont illustrés par les trois images de la figure II-16. La figure (a) présente une image issue dune des caméras, la figure (b) montre les maxima locaux extraits de cette image et la figure (c) présente les segments labellisés.


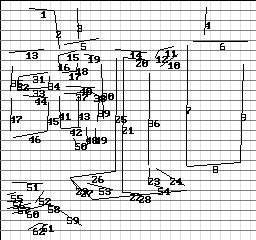
(a) : image originale (b) : Maxima locaux (c) : segments extraits
Image II-10
Le travail a porté par la suite sur lanalyse des paramètres calculés pour chaque segment et sur la recherche dune méthode de classification automatique des données stéréoscopiques. En effet, et cest également une des originalités de cette recherche, nous avons décidé de ne pas utiliser une méthode épipolaire pour apparier les segments [LOA00C].
Ce travail a été mené à travers quatre bases de données représentant un total de 2640 couples de segments bien ou mal appariés. Lutilisation de plusieurs méthodes danalyse de données nous a permis de restreindre lespace des paramètres associé à un segment. Nous sommes passé ainsi dune dimension 16 à une dimension 8. Cette étape nous a permis également de limiter la corrélation entre les paramètres et de valider la nature des attributs proposés. Puis nous avons cherché une méthode efficace et rapide permettant de juger de la validité de lappariement entre deux segments issus des deux images. Après avoir testé une méthode bayesienne et une méthode neuronale, nous avons chiffré lapport dune méthode par rapport à lautre et nous avons retenu la combinaison des deux méthodes à travers une fonction simple de type " somme " [BAR00C].
Lultime partie de ce travail porte sur la reconstruction de lespace du robot. Une fois les segments appariés, il fallait remonter aux coordonnées 3-D des objets présents dans la scène [LOA01R]. Nous avons pu ainsi analyser la précision de nos calculs et vérifier que les résultats étaient compatibles avec lapplication visée, à savoir le déplacement dun robot dans un environnement domestique. La précision finale proposée par le système est denviron 5cm dans le volume de calibration du capteur, soit à environ 2 mètres des objets.
Lensemble du travail décrit ici a été présenté dans le cadre de la soutenance de thèse dHumberto LOAÏZA [LOA99T].
Plusieurs éléments de cette étude peuvent donner lieu à une suite. Tout dabord, les caméras utilisées étaient des caméras noir et blanc, ce qui est peu compatible dans un environnement domestique. Nous allons donc transposer ce travail dans un environnement coloré. Ceci posera des problèmes tels que le choix de lespace des couleurs et la recherche dopérateurs efficaces dans la phase de segmentation. De nouveaux paramètres intervenant dans la caractérisation des segments, létape danalyse de données doit être reprise afin de valider les paramètres pertinents pour la phase dappariement. Par ailleurs, un travail sur la fonction de combinaison des classifieurs ainsi quune comparaison entre cette méthode dappariement et une méthode épipolaire seraient des éléments importants pour valider lintérêt de ce travail. Lapplication de cette recherche va trouver un débouché naturel dans le développement dune base mobile pour laide aux handicapés moteurs, étude menée sous la direction dEtienne COLLE. Un stage de DEA débutera en janvier sur cette thématique; stage qui devrait déboucher sur une thèse.
2.3.2. Technologie des moyens de traitement et de communication
La tendance à déporter des traitements, de plus en plus complexes au niveau du capteur intelligent, pose des problèmes de temps réel et darchitecture locale des moyens de calcul. La solution que nous proposons est une architecture multiprocesseur à base de circuits dédiés. La communication est basée sur la norme du réseau de terrain CAN qui définit en partie les deux couches du modèle OSI (Open System Interconnection). Nous travaillons actuellement à la définition de la couche logique de communication.
Plusieurs projets ont permis daborder laspect technologique :
- pour le Projet européen Brite Euram intitulé PALAIOMATION, l'objectif est de reproduire l'évolution d'espèces disparues. Le principe consiste à habiller un robot à pattes comportant une vingtaine d'actionneurs. Nous avons développé les cartes d'axes et surtout de la gestion de l'architecture multiprocesseur afin d'obtenir des mouvements réalistes. L'interconnexion des différents modules actionneur et capteur utilise le réseau de terrain CAN. Cet aspect architecture distribuée a été aussi traité par un contrat INRETS sur lInformatique embarquée sur un véhicule pour lassistance à la conduite [COL98RC],
- dans le projet avec lAFM (Association Française contre les myopathies) [HOP97T], une architecture multiprocesseur répartie est proposée pour la gestion dun robot mobile dassistance aux personnes handicapées,