



suivant: Convergence de la phase
monter: Résultats théoriques concernant l'algorithme
précédent: Résultats théoriques concernant l'algorithme
Table des matières
Nous abordons à présent l'aspect théorique de l'algorithme CbL
proposé dans la section précédente. À ce sujet, plusieurs
questions se posent:
- la phase de propagation se termine-t-elle toujours et
rend-elle le graphe cohérent ?
- l'algorithme d'apprentissage converge-t-il ?
- la politique de choix d'action a-t-elle un caractère d'optimalité ?
- quelle est la fiabilité de la politique de choix d'action
après apprentissage ?
- quelle est la prédictibilité associée à l'algorithme d'apprentissage ?
L'objectif de cette section est de répondre à ces questions. Voici
les principaux résultats.
- Nous montrons que la phase de propagation se termine toujours
(il n'y a pas de bouclage au cours de la modification des valeurs ``qualité'').
- D'autre part, la convergence de l'algorithme est établie.
- En utilisant la propriété (
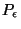 ), nous montrons que,
sous certaines conditions, s'il existe une politique de commande
fiable, permettant d'atteindre l'objectif à coup sûr, alors elle
est découverte: dans ce sens, la solution obtenue après
apprentissage est ``optimale'', même si ce terme a une portée plus
restreinte que pour les méthodes d'AR classique. En effet, toutes
les politiques de commande permettant d'atteindre l'objectif sont
équivalentes: l'algorithme ne permet pas de les discriminer en
dégageant la meilleure. Nous observerons ce point dans l'exemple
du labyrinthe fourni dans la prochaine section.
), nous montrons que,
sous certaines conditions, s'il existe une politique de commande
fiable, permettant d'atteindre l'objectif à coup sûr, alors elle
est découverte: dans ce sens, la solution obtenue après
apprentissage est ``optimale'', même si ce terme a une portée plus
restreinte que pour les méthodes d'AR classique. En effet, toutes
les politiques de commande permettant d'atteindre l'objectif sont
équivalentes: l'algorithme ne permet pas de les discriminer en
dégageant la meilleure. Nous observerons ce point dans l'exemple
du labyrinthe fourni dans la prochaine section.
suivant: Convergence de la phase
monter: Résultats théoriques concernant l'algorithme
précédent: Résultats théoriques concernant l'algorithme
Table des matières
2002-03-01