



suivant: Apprentissage perceptif (AP)
monter: Algorithme d'AO défini dans
précédent: Résultats
Table des matières
Nous avons construit un algorithme d'AO, appelé CbL pour
Constraint based Learning, qui est fondé sur la réaction du
système (qui est un graphe d'états possèdant chacun un marquage) à
un ensemble de contraintes. Nous avons achevé l'ensemble des
étapes de notre méthodologie:
- choix d'une contrainte qui s'applique au système d'AO,
qui est dérivée de l'algorithme minimax
- découverte de la manière d'assurer le respect de cette
contrainte à tout moment
- preuve que l'interaction avec l'environnement peut
s'interpréter comme un apprentissage
- preuve que cet apprentissage est prédictible et que,
s'il existe une solution à celui-ci, elle est fiable
Les caractéristiques de prédictibilité et de fiabilité sont donc
émergentes à partir de la spécification de notre contrainte d'équilibre.
L'adaptation du système à une modification de l'environnement est également
une propriété de l'algorithme CbL. Cependant, l'ensemble de ces résultats n'est
valable que si le contexte de l'AO est idéal (c'est-à-dire s'il vérifie
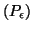 ).
Mais, l'influence du contexte est ici limitée à la topologie des états du système.
En effet, l'algorithme CbL ne comporte pas de paramètre susceptible de modifier le
résultat de l'apprentissage.
).
Mais, l'influence du contexte est ici limitée à la topologie des états du système.
En effet, l'algorithme CbL ne comporte pas de paramètre susceptible de modifier le
résultat de l'apprentissage.
Des exemples applicatifs simples appuient nos résultats théoriques.
Nous montrons que l'algorithme CbL converge nettement plus rapidement
que l'adatation
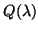 de l'algorithme du Q-Learning (10 fois pour un
problème simple et beaucoup plus pour un problème plus complexe). D'autre part,
nous en montrons l'incrémentalité. Lorsque la phase d'exploration est complète
(toutes les transitions du graphe d'état ont été explorées au moins une fois),
la politique de commande est optimale, sauf dans des cas très particuliers
qui peuvent être surmontés.
de l'algorithme du Q-Learning (10 fois pour un
problème simple et beaucoup plus pour un problème plus complexe). D'autre part,
nous en montrons l'incrémentalité. Lorsque la phase d'exploration est complète
(toutes les transitions du graphe d'état ont été explorées au moins une fois),
la politique de commande est optimale, sauf dans des cas très particuliers
qui peuvent être surmontés.
La première partie de notre travail est donc achevée avec succès.
Il nous reste à aborder la partie la plus délicate, concernant
l'AP. Nous rappellons que l'objectif de celle-ci est de permettre
la création d'un contexte idéal (au sens de la contrainte
(
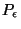 ) que nous avons définie dans le premier chapitre.
) que nous avons définie dans le premier chapitre.
suivant: Apprentissage perceptif (AP)
monter: Algorithme d'AO défini dans
précédent: Résultats
Table des matières
2002-03-01