



suivant: Constituants du processus de
monter: Introduction
précédent: Introduction
Table des matières
Nous avons émis le postulat que l'apprentissage se scinde en deux étapes
inter-connectées: la première étape concerne l'apprentissage perceptif (AP),
alors que la seconde traite de l'apprentissage de l'atteinte d'un objectif (AO).
La première partie de ce document a concerné l'AO. Nous supposons que celui-ci
est guidé par un ou des signaux pauvres, indiquant à tout moment si l'objectif
est atteint ou si la zone de viabilité du système est respectée: ainsi, le
mécanisme d'apprentissage que nous souhaitons pour l'AO est similaire à celui
des méthodes d'apprentissage par renforcement (AR). Le premier chapitre a montré
que le contexte de ces méthodes influence le résultat de l'apprentissage, ce
qui empêche de garantir la fiabilité![[*]](file:/usr/lib/latex2html/icons/footnote.png) de la politique de commande du système une fois l'apprentissage terminé; de plus,
il rend l'apprentissage peu prédictible. Pour répondre à ce problème, nous
avons introduit une notion de contexte idéal, associée à deux mesures
d'entropie
de la politique de commande du système une fois l'apprentissage terminé; de plus,
il rend l'apprentissage peu prédictible. Pour répondre à ce problème, nous
avons introduit une notion de contexte idéal, associée à deux mesures
d'entropie 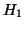 et
et 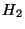 qui sont minimales pour ce contexte. Un tel contexte
répond à une contrainte, que nous avons appelée (
qui sont minimales pour ce contexte. Un tel contexte
répond à une contrainte, que nous avons appelée (
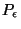 ). Celle-ci traduit
la possibilité de prédire avec un très grande exactitude à la fois l'état suivant
du système, connaissant l'état présent et la commande exécutée, mais aussi la
commande exécutée, connaissant deux états successifs du système. Utilisant la
démarche que nous nous sommes fixée dans les sections introductives, nous avons
établi une contrainte d'équilibre sur les qualités
associées aux états du système. Nous avons montré comment l'environnement agit
sur le système et comment ce dernier réagit dans le but de respecter cette contrainte.
Enfin, nous avons montré que cette adaptation peut être interprétée comme un
apprentissage, appelé Constraint based Learning ou CbL, lorsque le contexte
respecte (
). Dans ces conditions, nous avons prouvé que celui-ci
est prédictible et que les politiques de commandes trouvées comme solutions sont
fiables. En outre, nous avons montré les capacités d'incrémentalité de CbL et
comparé les performances de ce dernier à la méthode du Q-Learning.
). Celle-ci traduit
la possibilité de prédire avec un très grande exactitude à la fois l'état suivant
du système, connaissant l'état présent et la commande exécutée, mais aussi la
commande exécutée, connaissant deux états successifs du système. Utilisant la
démarche que nous nous sommes fixée dans les sections introductives, nous avons
établi une contrainte d'équilibre sur les qualités
associées aux états du système. Nous avons montré comment l'environnement agit
sur le système et comment ce dernier réagit dans le but de respecter cette contrainte.
Enfin, nous avons montré que cette adaptation peut être interprétée comme un
apprentissage, appelé Constraint based Learning ou CbL, lorsque le contexte
respecte (
). Dans ces conditions, nous avons prouvé que celui-ci
est prédictible et que les politiques de commandes trouvées comme solutions sont
fiables. En outre, nous avons montré les capacités d'incrémentalité de CbL et
comparé les performances de ce dernier à la méthode du Q-Learning.
L'objectif de l'AP est de fournir à l'AO un contexte respectant la propriété
(
). Le résultat de l'AP est la formation des états du système.
Conformément à notre postulat de départ (voir l'avant-propos), nous pensons que
l'AP est une propriété émergente, issue de contraintes d'équilibre appliquées
au processus de catégorisation.
Dans ce système, le rôle du processus de catégorisation est de déterminer
l'information perceptive à partir de deux entrées: le signal et la mémoire du
système. L'objectif de ce chapitre est de décrire une modélisation possible de
ce processus. Nous introduirons ainsi une méthode de sélection d'hypothèses
formant le corps de celui-ci. Nous décrirons également la nature de ces
hypothèses, constituant l'entrée ``mémoire''. En particulier, nous donnerons
l'ensemble des paramètres relatifs à celles-ci. Nous fournirons les algorithmes
de sélection qui sont à la base du processus de catégorisation, puisqu'ils
permettent de déterminer l'information perceptive qui découle de la combinaison
entre le signal d'entrée et la mémoire du système. Nous montrerons que, dans
certains cas, il est possible, grâce à la théorie du calcul sur les intervalles,
de déterminer de manière exacte et sûre deux ensembles encadrant l'ensemble des
solutions du problème de sélection.
Nous ferons le lien entre notre modélisation du processus de
catégorisation et des modélisations paramétriques existantes. Nous
montrerons en particulier qu'elle possède un caractère de
généricité permettant d'espérer une utilisation de ce modèle dans
un large domaine d'applications traitant de la perception. Comme
nous l'avons souligné dans les sections introductives, la
principale différence de notre approche par rapport à des
modélisations paramétriques classiques est d'essayer de
spécifier l'ensemble des valeurs admissibles de nos paramètres.
C'est précisément le rôle des contraintes que nous appliquerons à
notre système, qui vont définir l'information perceptive. Mais
nous n'aborderons pas l'examen de ces contraintes dans ce
chapitre. Celles-ci seront exposées dans le chapitre suivant et
permettront de restreindre l'ensemble des mémoires applicables à
l'entrée du processus de catégorisation.
suivant: Constituants du processus de
monter: Introduction
précédent: Introduction
Table des matières
2002-03-01