[Retour au sommaire] [suivant] [précédent]
2.2. VISION 2D/3D
L'analyse perceptuelle puis la modélisation et reconstruction 3D sont présentées successivement.
2.2.1. Analyse perceptuelle
Les travaux menés autour de ce concept se décomposent en trois parties : la première présente la calibration des différents capteurs utilisés (2D ou 3D), la seconde partie est axée sur l'analyse ou segmentation d'images (elle aussi en 2D ou 3D), afin d'en élever le contenu informationnel, la dernière partie porte sur les processeurs de traitement bas niveau.
2.2.1.1 - Calibration de caméras et de télémètres
Cette étape est nécessaire quels que soient les capteurs utilisés, et plus encore dès l'instant où leurs informations doivent être mises en commun. Elle permet d'exprimer les informations issues de chaque capteur par rapport à un référentiel commun en vue de localiser dans un environnement des objets ou des obstacles. Les différents capteurs utilisés sont des caméras, utilisées seules ou en stéréovision, un télémètre laser IR à temps de vol, monté sur une tourelle orientable en site et en azimut ; un télémètre par triangulation utilisant une caméra fixe et un pointeur laser visible monté sur une tourelle orientable également en site et en azimut [TRI96T], [CHA94C], [NZI95R], [TRI96R].
La calibration des caméras est effectuée à partir d'une modélisation linéaire pour les focales supérieures à 10 mm. La détermination des paramètres du modèle de projection est alors obtenue par un algorithme de type filtrage de Kalman (introduit par Ayache (INRIA)), lui-même pouvant être initialisé par une approche linéaire du critère des moindres carrés utilisant une pseudo-inverse. La cible est représentée par des points lumineux de position connue au 1/10 de mm, la détection de leurs images peut être maintenant subpixellique (1/10 ème de pixel).
Pour les objectifs à focale inférieure à 10 mm ou pour des objectifs de très faible coût, présentant des distorsions, nous avons modélisé celles-ci en tenant compte des distorsions radiales au premier ordre. La modélisation employée est celle introduite par Chaumette (IRISA) qui exprime les coordonnées pixels réelles en fonction des coordonnées linéaires et d'un facteur de distorsion. Pour résoudre ce problème, nous avons appliqué une méthode d'optimisation non-linéaire - Lenvenberg & Marquardt - qui permet de déterminer l'ensemble des paramètres (intrinsèques et extrinsèques) du modèle. Ces techniques sont maintenant bien connues de la communauté scientifique. Le laboratoire s'est attaché à développer une expertise approfondie du domaine car une calibration correcte est la condition première à réaliser pour faire des relevés 3D de qualité. A partir d'analyses de la robustesse, nous avons pu mettre en évidence que lorsque le modèle linéaire suffit, ce sont les paramètres globaux de projection qui sont les plus stables. Pour le modèle non linéaire, nous avons mis en évidence l'intérêt du choix correct de la base d'apprentissage, ainsi que l'intérêt de disposer d'une base de généralisation indépendante de la précédente pour déterminer la condition d'arrêt de l'algorithme [CHA98L]. Une procédure entièrement originale de calibration automatique robot/caméra qui permet de disposer de points de calibration dans tout l'espace de travail du robot a été développée au laboratoire [MAL98bC].
Ces travaux se poursuivent actuellement par la caractérisation d'une caméra munie d'un zoom montée sur une tête active [CHA98ST] et par la calibration d'un capteur bi-oculaire faible coût à fortes distorsions destiné à une application de robotique domestique [LOA98C].
Nous avons testé l'apport de techniques neuronales dans la calibration de caméra. Le modèle retenu a été celui des deux plans. La méthode développée est entièrement originale, elle permet de conduire l'apprentissage du modèle inverse séparément sur chacun des plans [BER95C].
La calibration d'objectifs à très grand angle a été effectuée dans le cadre de la coopération CEMIF/ ETL (Japon) sur l'objectif ESCHeR d'angle d'ouverture 120° [BER96aC].
Pour les télémètres temps de vol et par triangulation montés sur une tourelle à 2 degrés de liberté, nous avons défini, comme pour les caméras, un modèle interne (intrinsèque au dispositif de mesure) et un modèle externe caractérisant le situation du capteur par rapport au repère du monde. Comme ces modèles sont non linéaires, la méthode de calibration utilise, là aussi, un algorithme d'optimisation non linéaire. La méthodologie de choix des points d'apprentissage et de généralisation est la même que celle utilisée pour les caméras. Afin d'éviter toute ambiguïté de localisation des points 3D des diodes sensibles aux IR sont placées sur la mire de calibration [BARA97R], [BARA97C], [BARA98R], [TRI96C], [TRI96T].
2.2.1.2 - Analyse d'images
a- Analyse d'images de profondeur
Le groupe Vision 2D-3D du CEMIF-SC mène des recherches qui ont pour but l'exploitation des informations tridimensionnelles issues de capteurs 3D actifs. Ces capteurs fournissent une représentation point par point, avec des coordonnées X, Y et Z, des surfaces situées dans la zone de vue d'un capteur de distance. Ces travaux de recherche portent sur l'analyse des images tridimensionnelles ainsi obtenues, aussi appelées " images de profondeur ".
Les objectifs sont de détecter et de localiser, à partir d'une image de profondeur de la scène, des objets d'intérêt en environnement concret perçu de façon extéroceptive et non modélisable complètement.
Un premier travail permettant une aide à la perception de la profondeur a été réalisé pour une application de robotique téléopérée [BAR96T]. Cette aide consiste à ajouter une information de profondeur à l'image caméra sous la forme d'une image télémètrique transformée en fausses couleurs en fonction de la distance calculée. Les effets d'empreinte et de point de vue ont été corrigés avant cette superposition.
Des travaux sur la segmentation d'images de profondeur sont menés au laboratoire depuis Octobre 1997, avec le renforcement de l'équipe par un nouveau Maître de Conférence.
Après l'étude et l'analyse d'algorithmes existants et en se fondant sur les conclusions d'études expérimentales récentes, nous avons dissocié la segmentation d'images de profondeur en deux problèmes selon le type de scènes analysées, constituées d'objets polyédriques ou non. Nos recherches dans le domaine nous ont amené à développer un algorithme complet de segmentation d'images de profondeur. Après avoir apporté une solution au problème spécifique de la segmentation en surfaces planes, l'approche a été généralisée pour l'étendre à la segmentation en régions planes et courbes. Une des originalités de ces travaux réside dans la façon dont un ensemble d'attributs, tel que la normale et la courbure aux surfaces, sont estimés en chaque point. Elle met en oeuvre une structure de pyramide de graphes. Ce type d'approche pyramidale est une technique récente et prometteuse qui suscite un intérêt particulier en segmentation d'images.
A l'aide de segmentations témoins (voir figures II.5 et II.6) et de la définition de critères, une étude quantitative et comparative, menée de manière rigoureuse sur un grand nombre d'images réelles, a permis de mettre en avant les atouts de la méthode proposée (qualité chiffrée des résultats et temps de calcul) par rapport à d'autres méthodes existantes.
Une suite logique de ces travaux est de tenter de concevoir un système de perception multicapteur (ou multisensoriel) capable de combiner et de fusionner les informations complémentaires ou redondantes, acquises par des sources perceptuelles de natures hétérogènes. Dans cette combinaison de segmentations, le travail consiste à développer des techniques coopératives de fusion de données afin de réaliser la fusion de segmentation en régions d'images de nature différente. Le formalisme utilisé est celui de Dempster-Shafer. L'objectif est d'obtenir, à partir de deux images d'étiquettes, une troisième image dont la partition correspond davantage à la réalité du terrain.
Ce travail, mené en collaboration avec le laboratoire LASMEA (UMR CNRS 6602), a donné lieu à des
expérimentations plus que prometteuses (figures II.5 et II.6) puisqu'elles montrent une amélioration qualitative et quantitative des résultats obtenus sur les segmentations de profondeur à partir de segmentations de luminance de qualité moyenne. Ces travaux ont donné lieu à deux publications actuellement soumises.

Figure II.5: Image de réflectance de la scène
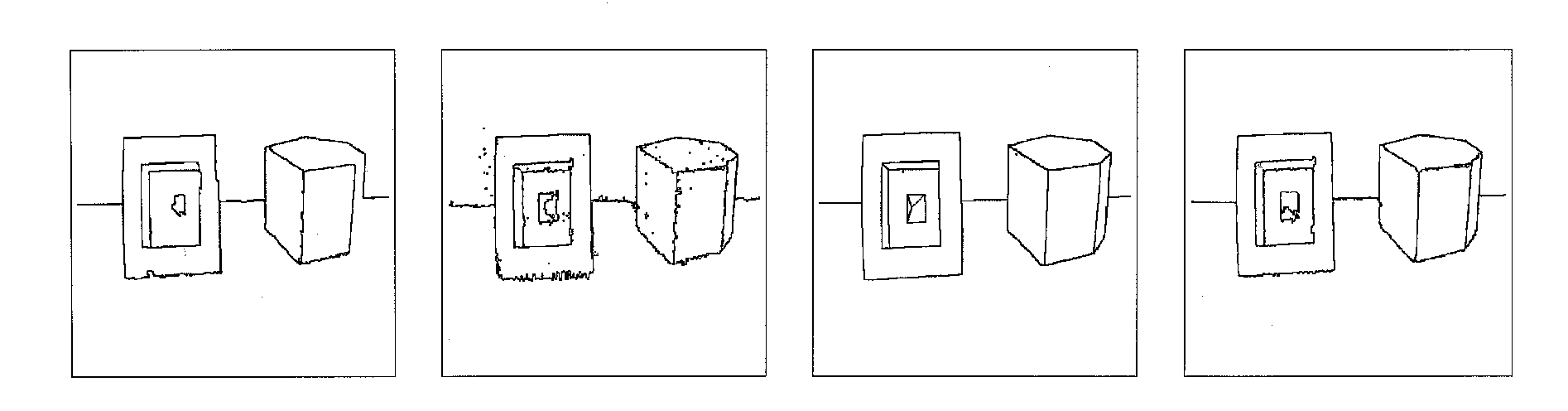
Figure II.6 : De gauche à droite, segmentation 2D, segmentation 3D, vérité terrain et résultats de la fusion des segmentations.
b - Analyse d'images de textures
Depuis plusieurs années, des travaux de recherche portant sur l'analyse, la segmentation et l'orientation de textures sont effectuées dans le groupe vision.
Intuitivement, la notion de texture nous paraît familière, mais en donner une définition précise devient plus complexe. Une texture est une information qui rend compte de l'état de surface d'un objet. Elle est caractérisée par l'arrangement plus ou moins régulier de motifs élémentaires. On distingue deux grandes classes de textures : les macrotextures, qui sont constituées par la répartition spatiale d'un ou plusieurs motifs élémentaires nommés texels, et les microtextures qui ont un aspect aléatoire mais pour lesquelles l'impression visuelle reste globalement homogène. Les textures donnent une information interne à une région. Dans des environnements flous ou perturbés, où l'information des contours n'est pas une donnée fiable, posséder une description de l'intérieur d'une région est un atout important. Les méthodes classiques d'analyse de textures sont très liées à la catégorie de textures à laquelle on s'intéresse. Pour les macrotextures, on utilisera de préférence des méthodes structurelles, tandis que l'analyse des microtextures se fera souvent par des méthodes de type statistiques.
b1 - Approche multirésolution pour l'analyse des textures
Avant de concevoir une méthode générale pour la caractérisation de textures variées, nous nous sommes attaché à la connaissance du phénomène. Nous avons développé un générateur de textures [CAI96ST] nous permettant de simuler certaines situations et nous avons étudié les variations des paramètres fournis par les opérateurs classiques [LEL95C]. Nous en avons déduit qu'une méthode unique n'était pas assez robuste face aux variations induites par le mouvement ou l'orientation et nous avons décidé de construire un algorithme basé sur une combinaison de méthodes.
La texture est un phénomène de type moyenne fréquence. Une analyse fréquentielle, assurée par une décomposition en ondelettes, couplée à une analyse statistiques réalisée par des opérateurs du type matrices de cooccurrences ou matrices de longueur de plages nous procure des résultats intéressants [ZAR96C]. La démarche développée est la suivante. Sur une image d'une texture nous calculons un vecteur de cinq paramètres issus d'analyse statistiques. Puis, nous décomposons l'image en quatre sous-images de résolution inférieure selon le schéma donné sur la figure II.7. Les filtres h et g sont des filtres miroirs en quadrature monodimensionnels, l'un de type passe-haut et l'autre passe-bas. Ces quatre sous-images s'obtiennent sans redondance d'information.
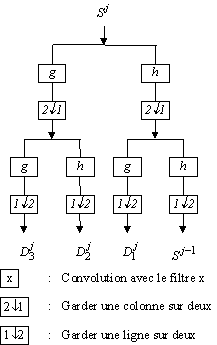
Figure II.7: Décomposition multirésolution d'une image
Cette décomposition se poursuit à des échelles inférieures et nous réalisons ainsi une décomposition en paquets incomplets d'ondelettes. En effet, le choix de poursuivre ou non la décomposition d'une sous-image est fait en fonction du contenu informationnel (au sens texture) de celle-ci. Sur chaque sous-image, à un niveau de décomposition donné, nous calculons le vecteur des cinq paramètres texturaux. Nous comparons ensuite ce vecteur à celui de l'image de résolution supérieure en calculant une distance entre les deux vecteurs. Si la distance est grande, cela signifie que l'information contenue dans l'image source est très peu présente dans cette sous-image, la décomposition peut donc s'interrompre. A l'inverse, si la distance est faible, cela induit que le contenu de cette sous-image est encore riche en information de type texture et qu'il est important de poursuivre la décomposition. La figure II.8 présente une image de texture (a) et le résultat de la décomposition obtenue (b).
Figure II.8 (a) Figure II.8 (b)
La méthode ainsi définie a été adaptée pour permettre d'aborder trois types de problèmes différents.
- La détection de défauts [LEL97C]
Dans le domaine industriel, et en particulier en contrôle qualité, de nombreuses applications nécessitent la recherche de défauts dans une surface qui n'est pas homogène (textile, bois, agro-alimentaire,...). L'information de texture, et la possibilité de déceler une rupture dans cette information, peut alors permettre la mise en évidence de ces défauts. L'intérêt de la démarche employée est qu'elle ne nécessite aucun apprentissage. Elle pourrait être complétée par une localisation des éventuels défauts.
- La classification de textures [ZAR97aC]
La classification de textures consiste à répondre à la question : " Est-ce que cet échantillon correspond à une texture connue ' " avec un taux de réussite important. L'approche de décomposition arborescente nous a permis de proposer une solution à ce problème. La méthode utilisée présente un taux de classification correcte compris entre 90% et 100% selon les échantillons.
- La segmentation d'images multi-texturées [ZAR97bC]
L'utilisation la plus ambitieuse de notre approche combinée multirésolution et analyse statistique porte sur la segmentation d'images composées de plusieurs textures. Le principe du traitement est le suivant : l'image à segmenter est décomposée de manière arborescente. On obtient donc un nombre, inconnu a priori, de feuilles qui ne sont pas toutes de la même taille. A partir d'un nombre restreint de ces feuilles, on reconstruit les images caractéristiques qui sont de taille égale à l'image initiale. Avant d'aborder la phase de classification des pixels, les images caractéristiques sont lissées, puis on effectue une étape de réduction de la dimension de l'espace de représentation en utilisant une transformation de Karhunen-Loeve. La classification, c'est-à-dire l'affectation de chaque pixel de l'image à une région de l'image présentant une caractéristique jugée homogène (ici la texture), est réalisée par une méthode de type "nuées dynamiques". La figure II.9 présente un exemple d'images comportant cinq textures (a) et le résultat de la segmentation obtenu par notre algorithme (b).
Poursuite de ce travail
Les suites de cette recherche vont porter d'une part, sur la phase de segmentation : amélioration des frontières, parallélisation de l'algorithme et, d'autre part, sur la prise en compte de la couleur dans l'analyse des textures.
Figure II.9 (a) Figure II.9 (b)
b2 - Reconnaissance de l'orientation de surfaces texturées
Le travail décrit ici est le fruit d'une collaboration entre le Département de Sciences Cognitives et Ergonomie de l'IMASSA-CERMA à Brétigny et le CEMIF-SC. Le but est de construire un système d'aide à la reconnaissances de formes dans des images de scènes naturelles. Les formes impliquées ne sont pas forcément de couleur ou de surface uniforme. Il faut donc être capable de reconnaître différentes faces d'un objet qui peuvent être vues sous différentes orientations de manière à les apparier ou bien de segmenter des formes qui auraient été attribuées indûment au même objet. Dans un premier temps, ce travail a porté sur une méthode permettant de séparer de microtextures des macrotextures [BOU97S]. En effet, les calculs d'orientation qui seront faits ne seront pas les mêmes dans les deux cas.
Pour les macrotextures, qui sont constituées d'éléments séparables appelés texels, c'est la variation de densité de ces éléments qui permet d'obtenir l'orientation du plan. Il faut donc d'abord extraire les texels de l'image, puis quantifier leur variation de densité [BOU96ST] et [BOU97C].
Pour les microtextures, le paramètre que nous utilisons pour déterminer l'orientation est fondée sur l'analyse des fréquences " locales " de l'image. Le travail effectué à tout d'abord consisté à calculer, de manière théorique, quelle serait la variation de fréquences locales dans une image pour une texture constituée d'une fréquence spatiale dominante orientée selon un angle de tilt et un angle de slant connus. Cette connaissance de la variation théorique permet de définir une courbe mathématique suivie par les fréquences locales dans l'image. L'interpolation de cette variation dans l'image devrait permettre de retrouver l'orientation d'une forme à partir de la carte des fréquences locales [BOU99C]. C'est cette méthode que nous avons développée dans un premier temps, pour des surfaces simples et des textures à une ou deux fréquences dominantes. La généralisation de la méthode est en cours. Conjointement à ces travaux, une étude a été faite sur les paramètres de prise de vue liés à la caméra ainsi qu'un calcul sur les incertitudes de mesure de manière à pouvoir apprécier la précision des résultats fournis par ces méthodes dites de " Shape From Texture ".
c - Processeurs spécialisés pour l'imagerie bas-niveau
Les travaux en cours comprennent essentiellement les recherches effectuées par D.Hanifi dans le cadre de la préparation de son doctorat sous la direction de M. SHAWKY. Ce dernier ayant quitté le CEMIF en septembre 1997, ces travaux ne perdureront pas au-delà de la soutenance de la thèse. Le thème principal de ces
recherches est : " Intégration du traitement bas niveau au capteur visuel (caméra) ".
D'une part, le travail porte sur l'implantation matérielle du traitement dit de bas niveau et, par ailleurs, il a pour but de remonter la barrière bas-haut niveau en intégrant également à l'implantation, des fonctions plus élaborées telle que l'étiquetage des points de contour. Les autres points développés au cours de cette thèse sont les suivants :
- développement d'une passerelle d'un langage orienté traitement d'images, notamment APPLY, vers le VHDL ou des hard-macros afin d'obtenir une architecture facilement programmable par un non-expert en électronique,
- élaboration d'une bibliothèque de fonctions matérielles de base pour le traitement d'images,
- logiciels/matériels utilisés : Chaîne de développement complète (simulation, routage) de MENTOR
GRAPHICS Version F.B, synthèse VHDL pour les produits FPGA de Xilinx ; matériel SUN 5.
Plusieurs publications dans des conférences et des revues ont été réalisées sur ce sujet [SHA96C], [HAN97C], [HAN98C], [SHA98C] et [SHA98R].
[Retour au sommaire] [suivant] [précédent]



