



suivant: À propos de ce
monter: corpus
précédent: Preuve de la proposition
Table des matières
- Abott, 1952
-
Abott, E. (1952).
Flatland. A Romance in Many Dimensions.
Dover Publications, New York.
- Albus, 1971
-
Albus, J. (1971).
A theory of cerebellar function.
Mathematical Biosciences, 10:25-61.
- Albus, 1981
-
Albus, J. (1981).
Brain, Behavior, and Robotics.
Byte Books.
- Ameisen, 1999
-
Ameisen, J. (1999).
La scupture du vivant. Le suicide cellulaire ou la mort
créatrice.
Seuil.
- Anderson, 1989
-
Anderson, C. (1989).
Learning to control an inverted pendulum using neural networks.
IEEE Control Systems Magazine, 9(3):31-37.
- Bain, 1873
-
Bain, A. (1873).
Mind and Body. The Theories of Their Relation.
Henry King, London.
- Baird, 1995
-
Baird, L. C. (1995).
Residual algorithms: Reinforcement learning with function
approximation.
Proceedings of the Twelfth International Conference on Machine
Learning, pages 30-37.
- Barto et al., 1983
-
Barto, A., Sutton, R., and Anderson, C. (1983).
Neurolike adaptive elements that can solve difficult learning control
problems.
IEEE Transactions on Systems, Man, and Cybernetics,
SMC13:834-846.
- Bellman, 1957
-
Bellman, R. (1957).
Dynamic Programming.
Princeton University Press, Princeton, NJ.
- Bersekas et Tsitsiklis, 1996
-
Bersekas, D. and Tsitsiklis, J. (1996).
Neuro-dynamic Programming.
Athena Press.
- Bersini et Gorrini, 1996
-
Bersini, H. and Gorrini, V. (1996).
Three connectionist implementations of dynamic programming for
optimal control: A preliminary comparative analysis.
In Workshop on Neural Networks for Identification and Control in
Robotics.
- Berthoz, 1997
-
Berthoz, A. (1997).
Le sens du mouvement.
Odile Jacob.
- Bertsekas, 1987
-
Bertsekas, D. (1987).
Dynamic Programming.
Prentice Hall.
- Bouchon, 1988
-
Bouchon, B. (1988).
Entropic models: a general framework for measures of uncertainty and
information.
Logic in Knowledge-Based Systems, Decision and Control, pages
93-105.
- Bouchon-Meunier, 1989
-
Bouchon-Meunier, B. (1989).
Incertitude, information, imprécision: une réflexion sur l'évolution
de la théorie de l'information.
Revue Internationale de Systémique, 3(4):375-385.
- Brooks, 1986
-
Brooks, R. A. (1986).
A robust layered control system for a mobile robot.
IEEE Journal of Robotics and Automation, RA-2(1):14-23.
- Carnap, 1950
-
Carnap, R. (1950).
Logical Foundations of Probability.
University of Chicago Press.
- Changeux, 1983
-
Changeux, J. (1983).
L'homme neuronal.
Fayard.
- Damasio, 1994
-
Damasio, A. (1994).
Descartes'Error: Emotion, Reason and the Human Brain.
Picador.
- Damasio, 1999
-
Damasio, A. (1999).
Le sentiment même de soi - Corps, émotions, conscience.
Editions Odile Jacob Sciences.
- Daubechies, 1992
-
Daubechies, I. (1992).
Ten Lectures on Wavelets, volume 61 of CBMS-NSF Regional
Conference Series in Applied Mathematics.
SIAM, Philadelphia.
- Davesne et Barret, 1999a
-
Davesne, F. and Barret, C. (1999a).
Constraint based memory units for reactive navigation learning.
In European Workshop on Learning Robots.
- Davesne et Barret, 1999b
-
Davesne, F. and Barret, C. (1999b).
Reactive navigation of a mobile robot using a hierarchical set of
learning agents.
In IROS'99.
- Dayan, 1992
-
Dayan, P. (1992).
The convergence of td(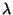 ) for general .
) for general .
Machine Learning, 8:341-362.
- Dayan et Sejnowski, 1994
-
Dayan, P. and Sejnowski, T. (1994).
Td() converges with probability 1.
Machine Learning, 14:295-301.
- Denton, 1985
-
Denton, M. (1985).
Evolution: Une théorie en crise.
Flammarion.
- d'Espagnat, 1985
-
d'Espagnat, B. (1985).
Une incertaine réalité.
Gauthier-Villars.
- d'Espagnat, 1994
-
d'Espagnat, B. (1994).
Le réel voilé.
Fayard.
- Edelman, 1992
-
Edelman, G. (1992).
Bright Air, Brilliant Fire: On the Matter of Mind.
Basic Books, New York.
- Gaussier et al., 1997
-
Gaussier, P., Joulain, C., Zrehen, S., Banquet, J., and Revel, A. (1997).
Visual navigation in an open environment without map to appear in
iros conference grenoble.
- Gaussier et Zrehen, 1995
-
Gaussier, P. and Zrehen, S. (1995).
Perac: A neural architecture to control artificial animals.
Robotics and Autonomous Systems, 16(2-4):291-320.
- Glorennec, 1994
-
Glorennec, P. (1994).
Fuzzy q-learning and dynamical fuzzy q-learning.
In FUZZ-IEEE'94, Orlando.
- Harnad, 1992
-
Harnad, S. (1992).
Cognition and the symbol grounding problem.
Electronic symposium on computation.
- Hartley, 1928
-
Hartley, R. (1928).
Transmission of information.
Bell System technical Journal, 7:535-563.
- Hebb, 1949
-
Hebb, D. (1949).
The Organization of Behavior.
John Wiley & Sons, New York.
- Hilbert, 1928
-
Hilbert, D. et Ackermann, W. (1928).
Grundzuge der Theoretischen Logik.
Springer, Berlin.
- Hsu et al., 1990
-
Hsu, F., Anantharaman, T., Campbell, M., and Nowatzyk, A. (1990).
A grandmaster chess machine.
Scientific American, 263(4):11-50.
- Jacobs, 1993
-
Jacobs, O. (1993).
Introduction to Control Theory.
Oxford University Press.
- James, 1890
-
James, W. (1890).
Principles of Psychology.
Henry Holt, New York.
- Jaulin et Walter, 1993
-
Jaulin, L. and Walter, E. (1993).
Set inversion via interval analysis for non-linear bounded
estimation.
Automatica, 29(4):1053-1064.
- Jaulin et al., 1996
-
Jaulin, L., Walter, E., and Didrit, O. (1996).
Guaranteed robust nonlinear parameter bounding.
In CESA'96 IMACS Multiconference Symposium on Modelling,
Analysis and Simulation, volume 2, pages 1156-1163, Lille.
- Jouffe, 1997
-
Jouffe, L. (1997).
Apprentissage de systèmes d'inférence floue par des méthodes de
renforcement: application à la régulation d'ambiance dans un bâtiment
d'élevage porcin.
Thèse de doctorat, Université de Rennes 1.
- Jutten et Herault, 1991
-
Jutten, C. and Herault, J. (1991).
Blind separation of sources, part i: An adaptive algorithm based on
neuromimetic architecture.
Signal Processing, 24:1-10.
- Kaebling et al., 1996
-
Kaebling, L., Littman, M., and Moore, A. (1996).
Reinforcement learning: A survey.
Journal of Artificial Intelligence Research, 4:237-285.
- Kahneman et Tversky, 1979
-
Kahneman, D. and Tversky, A. (1979).
Prospect theory: An analysis of decision under risk.
Econometrica, 47:263-291.
- Kalman, 1960
-
Kalman, R. (1960).
A new approach to linear filtering and prediction problems.
Transaction of the ASME - Journal of Basic Engineering, pages
35-45.
- Kohonen, 2001
-
Kohonen, T. (2001).
Self-Organizing Maps, volume 30.
Springer Series in Information Sciences, Berlin.
- Lecerf, 1997
-
Lecerf, C. (1997).
Une leçon de piano ou la double boucle de l'apprentissage
cognitif, volume 3.
Travaux et Documents, Université Paris 8 Vincennes-Saint-Denis.
- Lin et Kim, 1991
-
Lin, C. and Kim, H. (1991).
Cmac-based adaptive critic self-learning control.
IEEE Transactions on Neural Networks, 2:530-533.
- Lin, 1992
-
Lin, L.-J. (1992).
Self-improving reactive agents based on reinforcement learning,
planning and teaching.
Machine Learning, 8:293-321.
- Maaref et al., 1999
-
Maaref, H., Barret, C., and Amamou, A. (1999).
Optimization of a fuzzy controller for a reactive navigation.
Computational Intelligence and Applications, pages 193-197.
- McCulloch et Pitts, 1943
-
McCulloch, W. and Pitts, W. (1943).
A logical calculus of the ideas immanent in nervous activity.
Bulletin of Mathematical Biophysics, 5:115-137.
- McGovern et al., 1998
-
McGovern, A., Precup, D., Ravindran, B., Singh, S., and Sutton, R. (1998).
Hierarchical optimal control of mdps.
Proceedings of the Tenth Yale Workshop on Adaptive and Learning
Systems, pages 186-191.
- Meyer et Wilson, 1991
-
Meyer, J. and Wilson, S. (1991).
editors: Proceedings of the first international conference on
simulation of adaptive behavior - from animals to animats.
- Michel, 1996
-
Michel, O. (1996).
Khepera simulator package version 2.0: Freeware mobile robot
simulator.
http://wwwi3s.unice.fr/~om/khep-sim.html.
- Mondada et al., 1994
-
Mondada, F., Franzi, E., and Ienne, P. (1994).
Mobile robot miniaturization: A tool for investigation in control
algorithms.
In Yoshikawa, T. and Miyazaki, F., editors, Proceedings of the
Third International Symposium on Experimental Robotics 1993, pages 501-513.
Springer Verlag,.
- Moore, 1979
-
Moore, R. (1979).
Methods and Applications of Interval Analysis.
SIAM, Philadelphia.
- Munos, 1997
-
Munos, R. (1997).
Apprentissage par Renforcement, Étude du cas Continu.
Thèse de doctorat, EHESS, CEMAGREF.
- Nowé, 1995
-
Nowé, A. (1995).
Fuzzy reinforcement learning: an overview.
Advances in fuzzy theory and technology.
- O'Regan et Noë, 2001
-
O'Regan, J. and Noë, A. (2001).
A sensorimotor account of vision and visual consciousness.
Behavioral and Brain Sciences, 24(5).
- O'Regan et al., 1999
-
O'Regan, J., Rensink, R., and Clark, J. (1999).
Blindness to scene changes caused by mudsplashes.
Nature, 398.
- Pavlov, 1927
-
Pavlov, I. (1927).
Conditionned refexes.
Oxford University Press.
- Pendrith, 1994
-
Pendrith, M. (1994).
On reinforcement learning of control actions in noisy and
non-markovian domains.
Technical report, UNSW Computer Science and Engineering.
- Pendrith, 1999
-
Pendrith, M. (1999).
Reinforcement learning in situated agents: Some theoretical problems
and practical solutions.
In 8th European Workshop on Learning Robots.
- Pendrith et McGarity, 1998
-
Pendrith, M. and McGarity, M. (1998).
An analysis of direct reinforcement learning in non-markovian
domains.
The Fifteenth International Conference on Machine Learning.
- Peng et Williams, 1996
-
Peng, J. and Williams, R. (1996).
Incremental multi-step q-learning.
Machine Learning, 22:283-290.
- Pham et al., 1992
-
Pham, D., Garrat, P., and Jutten, C. (1992).
Separation of a mixture of independent sources through a maximum
likelihood approach.
In Proc. EUSIPCO, pages 771-774.
- Pitrat, 1990
-
Pitrat, J. (1990).
Métaconnaissance - Futur de l'intelligence artificielle.
Hermès.
- Pradel et Barret, 1998
-
Pradel, G. and Barret, C. (1998).
Environment recognition in mobile robotics by means of neural
networks.
Journal Européen des Systèmes Automatisés, 32:939-963.
- Quinlan, 1984
-
Quinlan, J. (1984).
Learning efficient classification procedures and their application to
chess endgames.
Machine Learning. An Artificial Approach, pages 463-482.
- Rasmussen, 1986
-
Rasmussen, J. (1986).
Information Processing and Human-Machine Interaction; An
approach to cognitive engineering.
Elsevier Science Publishing Co, North-Holland.
- Reeke et al., 1990
-
Reeke, G., Sporns, O., and Edelman, G. (1990).
Synthetic neural modeling: The ``darwin'' series of recognition
automata.
Proc. of the IEEE, 78(9):1498-1530.
- Reich, 1949
-
Reich, W. (1949).
L'analyse caractérielle.
Payot.
- Revel, 1997
-
Revel, A. (1997).
Contrôle d'un robot mobile autonome par approche
neuromimétique.
Thèse de doctorat, Université de Cergy-Pontoise.
- Rich, 1983
-
Rich, E. (1983).
Artificial Intelligence.
McGraw-Hill.
- Rosenblatt, 1958
-
Rosenblatt, F. (1958).
The perceptron: A probabilistic model for information storage and
organization in the brain.
Psychological Review, 65:386-408.
- Rumelhart et al., 1986
-
Rumelhart, D., Hinton, G., and Williams, R. (1986).
Learning internal representations by error propagation.
Nature, 323:533-536.
- Rummery, 1995
-
Rummery, G. (1995).
Problem Solving with Reinforcement Learning.
PhD thesis, Cambridge University.
- Samuel, 1959
-
Samuel, A. (1959).
Some studies in machine learning using the game of checkers.
IBM Journal of Research and Development, 3:211-229.
- Sauvage, 1999
-
Sauvage, G. (1999).
Les marchés financiers. Entre hasard et raison: le facteur
humain.
Seuil.
- Schwartz, 1993
-
Schwartz, A. (1993).
A reinfocement learning method for maximising undiscounted rewards.
Proceeding of Int. Conf. on Machine Learning.
- Shannon, 1948
-
Shannon, C. (1948).
A mathematical theory of communication.
Bell System technical Journal, 27:379-423,623-656.
- Shortliffe et Buchanan, 1975
-
Shortliffe, E. and Buchanan, B. (1975).
A model of inexact reasoning in medicine.
Mathematical Biosciences, 23:351-379.
- Sutton, 1984
-
Sutton, R. (1984).
Temporal Credit Assignment in Reinforcement Learning.
PhD thesis, University of Massachusetts, Amherst, MA.
- Sutton, 1988
-
Sutton, R. (1988).
Learning to predict by the method of temporal differences.
Machine Learning, 3:9-44.
- Sutton, 1996
-
Sutton, R. (1996).
Generalization in reinforcement learning: Successful examples using
sparse coarse coding.
Advances in Neural Information Processing Systems: Proceedings
of the 1995 Conference, pages 1038-1044.
- Sutton et Barto, 1998
-
Sutton, R. and Barto, A. (1998).
Reinforcement Learning: An introduction.
MIT Presss, Cambridge, MA.
- Tanaka, 1995
-
Tanaka, K. (1995).
Stability and stabilizability of fuzzy-neural control systems.
IEEE Transactions on Fuzzy Systems, 3(4):438-447.
- Tesauro, 1994
-
Tesauro, G. (1994).
Td-gammon, a self-teaching backgammon program, achieves masterlevel
play.
Neural Computation, 6:215-219.
- Thagard et Barnes, 1996
-
Thagard, P. and Barnes, A. (1996).
Emotional decisions.
Proceedings og the Eighteenth Annual Conference of The Cognitive
Science Society, pages 426-429.
- Thagard et Millgram, 1997
-
Thagard, P. and Millgram, E. (1997).
Inference to the best plan: A coherence theory of decision.
Goal-Driven Learning, pages 439-454.
- Touzet et al., 1995
-
Touzet, C., Sehad, S., and Giambiasi, N. (1995).
Improving reinforcement learning of obstacle avoidance behavior with
forbidden sequences of actions.
In International Conference on Robotics and Manufacturing,
Cancun, Mexico, 14-16 June 1995.
- Tsitsiklis et Roy, 1996
-
Tsitsiklis and Roy, V. (1996).
Feature-based methods for large scale dynamic programming.
Machine Learning, 22:59-94.
- Tsitsiklis, 1994
-
Tsitsiklis, J. (1994).
Asynchronous stochastic approximation and q-learning.
Machine Learning, 16:185-202.
- Turing, 1936
-
Turing, A. (1936).
On computable numbers, with an application to the
entscheidungsproblem.
Proceedings of the London Mathematical Society, 42(2):230-265.
- Turing, 1950
-
Turing, A. (1950).
Computing machinery and intelligence.
Mind, 59:433-460.
- Tversky et Kahneman, 1981
-
Tversky, A. and Kahneman, D. (1981).
The framing of decisions and the psychology of choice.
Science, 211:453-458.
- Wang et al., 1996
-
Wang, H., Tanaka, H., and Griffin, M. (1996).
An approach to fuzzy control of nonlinear systems: Stability and
design issues.
IEEE Transactions on Fuzzy Systems, 4(1):14-23.
- Watkins, 1989
-
Watkins, C. (1989).
Learning from Delayed Rewards.
PhD thesis, King's College, Cambridge, UK.
- Weizenbaum, 1976
-
Weizenbaum, J. (1976).
Computer Power and Human Reason.
W.H. Freeman.
- Whitehead, 1992
-
Whitehead, S. (1992).
Reinforcement Learning for the Adaptive Control of Perception
and Action.
PhD thesis, King's College, Cambridge, England.
- Wiering, 1999
-
Wiering, M. (1999).
Explorations in Efficient Reinforcement Learning.
PhD thesis, Universiteit van Amsterdam.
- Wiering et Schmidhuber, 1997
-
Wiering, M. and Schmidhuber, J. (1997).
Hq-learning.
In Adaptive Behavior, volume 6:2, pages 219-246.
2002-03-01