



suivant: Guide du chapitre
monter: Introduction
précédent: Introduction
Table des matières
La commande d'un processus peut être facilitée par l'utilisation
de techniques d'apprentissage. Cela permet, dans certains cas,
d'éviter une modélisation théorique trop complexe, voire impossible
à réaliser. Nous avons souligné dans l'avant-propos que les techniques
d'apprentissage conventionnelles (supervisé, semi-supervisé ou non
supervisé) ne permettent pas de garantir la nature du résultat: un
échec de l'algorithme d'apprentissage signifie-t-il qu'il n'existe
pas de solutions au problème ? Une réussite de l'apprentissage
signifie-t-elle que la solution est fiable ? On ne peut pas répondre
à ces questions. Dans les cas d'applications réelles, il est souvent
très délicat d'apprécier l'adéquation entre le contexte fourni par
l'expérimentateur et l'algorithme d'apprentissage: cela nuit à la
prédictibilité du résultat de l'apprentissage ainsi qu'à la fiabilité
de la politique de commande obtenue. L'objectif de ce chapitre est de
montrer que le contexte de l'algorithme d'apprentissage est responsable
de cette incertitude. Nous rassemblons dans le terme ``contexte''
l'ensemble des données et modèles utilisés par la méthode d'apprentissage,
sans que celle-ci puisse les modifier au cours de son exécution.
Pour étayer notre propos, nous nous focaliserons sur une méthode
d'apprentissage par renforcement (AR) classique: le Q-Learning.
Les méthodes d'AR offrent l'avantage de construire, par essais/erreurs
successifs, un mécanisme de réflexe perception/action optimal, sans
nécessiter l'utilisation d'un modèle: le système doit seulement connaître
à tout moment de l'apprentissage si l'objectif est atteint ou non. Notre
choix s'est porté sur cette catégorie de méthodes semi-supervisées, car
la phase d'apprentissage de l'atteinte d'un objectif (AO) que nous avons
considérée dans la partie introductive de notre document, utilise également
un signal de retour pauvre. Nous souhaitons ainsi montrer les problèmes que
notre système d'apprentissage à deux niveaux devra éviter.
Le contexte particulier aux méthodes d'AR est composé des éléments suivants:
- la nature et de la qualité des signaux d'entrée du système
- la modélisation du processus de décision par une chaîne de Markov,
voire une chaîne de Markov cachée
- la manière d'utiliser les signaux d'entrée pour déterminer l'état
courant du système (ce que nous nommerons topologie des états du système)
- la politique d'exploration de l'espace d'états
Chacun de ceux-ci est une cause potentielle d'échec de l'apprentissage.
Nous allons illustrer cela à travers un exemple applicatif simple: le
problème du pendule inversé. Nous l'avons choisi parce qu'il est un banc
d'essai classique en AR et qu'il est particulièrement sensible à la qualité
du contexte d'apprentissage: deux ou trois mauvaises commandes consécutives
peuvent mettre le système en échec. Nous nous intéresserons plus
particulièrement à l'influence du contexte d'apprentissage sur la
fiabilité du système.
Cependant, nous ne limitons pas notre travail à une simple constatation.
Nous essayons de préciser les causes possibles des échecs. Pour cela,
nous allons considérer le graphe d'états du système (chaque transition
correspond au passage du système d'un état 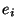 à un état
à un état 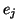 par
une commande
par
une commande 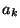 ). Nous mettons en évidence la relation entre la
dégradation des résultats du système et l'augmentation du nombre de
transitions différentes, partant du même état en exécutant la
même commande . Cette dégradation a également un rapport avec
l'augmentation du nombre de transitions d'un état vers un état
(l'exécution de plusieurs commandes aboutit au même état). Ces
deux phénomènes ont un rapport direct avec la quantité d'information
(au sens de Shannon) portée par l'exécution d'une commande, connaissant
l'état courant (pouvoir discriminant des commandes sur la nature de
l'état d'arrivée
). Nous mettons en évidence la relation entre la
dégradation des résultats du système et l'augmentation du nombre de
transitions différentes, partant du même état en exécutant la
même commande . Cette dégradation a également un rapport avec
l'augmentation du nombre de transitions d'un état vers un état
(l'exécution de plusieurs commandes aboutit au même état). Ces
deux phénomènes ont un rapport direct avec la quantité d'information
(au sens de Shannon) portée par l'exécution d'une commande, connaissant
l'état courant (pouvoir discriminant des commandes sur la nature de
l'état d'arrivée ![[*]](file:/usr/lib/latex2html/icons/footnote.png) ) et
avec la quantité d'information portée par la connaissance de l'état
d'arrivée (pouvoir discriminant de la connaissance de l'état d'arrivée
pour déterminer l'action qui vient d'être exécutée). Nous
utiliserons donc naturellement deux mesures d'entropie
) et
avec la quantité d'information portée par la connaissance de l'état
d'arrivée (pouvoir discriminant de la connaissance de l'état d'arrivée
pour déterminer l'action qui vient d'être exécutée). Nous
utiliserons donc naturellement deux mesures d'entropie 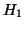 et
et 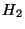 pour quantifier la qualité du contexte d'apprentissage et donner une
relation avec le degré de fiabilité du résultat d'apprentissage.
pour quantifier la qualité du contexte d'apprentissage et donner une
relation avec le degré de fiabilité du résultat d'apprentissage.
Nous montrons également que certains facteurs du contexte d'apprentissage
peuvent être modélisés comme des sources d'erreur, caractérisées par une
fréquence d'occurrence des erreurs propre à ces sources.
L'ensemble de cette étude nous permet donc de mieux comprendre par
quels mécanismes le contexte influence le résultat de
l'apprentissage. Ces résultats nous sont utiles pour définir ce
que pourrait être un contexte idéal (minimisant et
). Nous rappelons ici notre idée générale qu'un système
d'apprentissage doit comprendre deux processus inter-connectés:
- apprentissage de la perception (AP): construction d'une source
fiable d'informations perceptives , à partir de données réelles
imprécises. Il s'agit d'obtenir une faculté de catégorisation
- apprentissage de l'atteinte d'objectifs (AO): construction
d'une stratégie d'atteinte d'objectif, utilisant ces informations
fiables comme données d'entrée
Dans ce cadre, le rôle de l'AP consiste à créer un contexte idéal
pour l'AO. Nous montrerons dans le chapitre suivant que ce
contexte permet effectivement d'obtenir des propriétés de
fiabilité du résultat de l'apprentissage ainsi que de
prédictibilité de l'algorithme d'AO. L'AP sera abordé dans la
deuxième partie de ce document de thèse.
suivant: Guide du chapitre
monter: Introduction
précédent: Introduction
Table des matières
2002-03-01