|
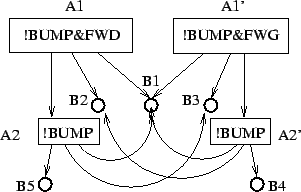
Les flèches signifient ``peut utiliser''. Cela signifie, par exemple, que la tâche A1 (suivi de mur sur la droite) est une séquence de trois tâches plus élémentaires:
B1, B2 et A2. B1 et B2 sont non décomposables. Par contre, A2 (évitement d'obstacle sur la gauche) est une séquence des trois actions élémentaires
B1, B3 et B5. Les contraintes associées à la bonne exécution de chacune des tâches non élémentaires à apprendre (
A1, A'1, B1 et B'1) sont notées dans les rectangles. |
![\begin{algo}[b]
\medskip {}
\textbf{[atteindre l'objectif]}
Si l'objectif est de...
...nt \lq\lq suivre un mur sur la gauche (resp. sur la droite)'' est utilisé.
\end{algo}](img186.gif)