Réflexions préliminaires
Le travail que nous avons effectué avait initialement pour objectif l'étude et l'application de méthodes d'apprentissage par renforcement (AR) dans le contexte de la robotique mobile. En effet, ces techniques, qui ont connu un réel essor à partir du début des années 1980 [Barto et al., 1983]1, possèdent des propriétés intéressantes, en particulier pour ce domaine d'application: ces méthodes sont fondées sur la Programmation Dynamique et des preuves théoriques de convergence sont établies; de plus l'apprentissage est incrémental et peut fonctionner dans le cadre d'un problème en temps réel à partir d'informations pauvres sur l'objectif à atteindre 2, sans nécessiter la connaissance a priori d'un modèle de l'environnement. En résumé, ces techniques permettent théoriquement à un robot d'apprendre une tâche particulière par essais/erreurs successifs, sans qu'on lui montre comment il doit effectuer cette tâche: il s'agit d'un apprentissage semi-supervisé, guidé uniquement par la connaissance d'un signal binaire, qui indique si l'objectif est atteint ou non (comportement réalisé avec succès ou échec).
Du point de vue de l'ingénieur, l'idée induite par la méthode d'AR est particulièrement séduisante, dans le cadre de la conception de facultés ``intelligentes'' d'un robot mobile autonome: il suffit de générer correctement le signal de renforcement, sous-tendant l'objectif à atteindre, pour que le robot construise, à l'aide de ce signal, une politique de choix d'actions (dont la théorie dit qu'elle possède un caractère d'optimalité) générant une séquence de commandes de base. De plus, l'apprentissage étant incrémental, cette séquence peut être adaptée si l'expérience montre que l'environnement a changé. Nous avons donc un algorithme qui, en puissance, possède tous les atouts dont l'utilisateur est friand: études préliminaires réduites très fortement et réutilisabilité, puisque l'environnement n'a pas besoin d'être modélisé, et garanties sur le résultat de l'apprentissage (preuves de convergence de l'algorithme vers un optimum). Ainsi, à partir de techniques d'AR, on peut, en théorie, programmer le robot à partir d'une architecture mixte: les modules qu'on sait programmer ``facilement'' et en peu de temps seraient construits d'une manière classique (programmation ad hoc), alors que les modules demandant a priori une grande expertise et un temps de développement important s'ils étaient conçus ``à la main'' pourraient être bâtis par apprentissage. Ce point de vue est d'autant plus séduisant qu'il correspond en quelque sorte à la construction des facultés humaines: nous apprenons à marcher ou à faire du vélo par une technique d'essais/erreurs, mais nous possédons également des comportements innées.
C'est donc dans ce contexte particulièrement prometteur que nous avions abordé l'étude et l'application des méthodes d'AR. Cependant, l'expérience a montré que cet optimisme doit être notablement tempéré, en particulier dans notre domaine d'application. Les objections que nous allons donner sont parfaitement connues et ont trouvé des réponses partielles: elles concernent principalement l'importance de l'hypothèse markovienne et la dualité exploration/exploitation, liée avec la possibilité d'apport de connaissances a priori. L'hypothèse majeure stipule que le processus décisionnel étudié est markovien (MDP): elle est à la base des preuves de convergence de l'algorithme [Dayan et Sejnowski, 1994] [Munos, 1997]. Cette hypothèse signifie que la probabilité de passage d'un état et à un état et + 1 ne dépend que de la connaissance de et: il en résulte que le choix d'une action à l'instant t peut être effectué sans faire appel à la mémoire du système et, en particulier, aux états passés (
et - 1, et - 2, etc.). En pratique, cette hypothèse est parfois trop restrictive, ce qui a donné lieu à l'étude des processus markoviens étendus 3ou partiellement observables (POMDP)4 [Chrisman, 1991],[Littman, 1994],[Littman et al., 1995].
Ainsi, la spécification exacte des états du système (ou des observations induisant ces états) est une condition nécessaire indispensable pour le problème d'AR, et c'est un travail non automatique, à effectuer lors de la phase préliminaire à l'apprentissage proprement dit. Cette spécification peut être triviale, en particulier dans le cas où le problème à traiter contient un nombre fini d'états non ambigus. Dans ce cas, les techniques d'AR fonctionnent bien. Cependant, ce n'est pas toujours vrai lorsque ces états sont créés à partir de données perceptives, issues de capteurs. Dans ce cas, il y a de fortes chances pour que le processus soit non-markovien et que la convergence des algorithmes d'AR soit compromise ou - ce qui est un moindre mal - que certains paramètres internes soient délicats à régler pour obtenir la convergence [Pendrith et McGarity, 1998] [Pendrith, 1999]. Nos premières expériences concernant l'apprentissage de tâches simples par un robot mobile Khepera 5simulé6 ont confirmé cet état de fait. Et, dans un cadre plus général, il a été montré [Bersini et Gorrini, 1996] que la plage des valeurs acceptables de certains paramètres internes pour que l'algorithme converge effectivement vers une solution acceptable est faible.
Le point crucial est le découpage de l'espace de perception afin de dégager des zones ``intéressantes'' pour le problème posé 7. Par ``intéressantes'', nous entendons qu'elles sont susceptibles d'être associées chacune à un état. L'importance de l'association perception/état peut être illustrée simplement grâce au cas d'école posé par la résolution du problème du pendule inversé grâce à une technique d'AR [Barto et al., 1983]. Dans ce cas précis, l'espace d'états n'avait pas été découpé au hasard: un découpage légèrement différent peut faire échouer l'apprentissage (un découpage en ``boîtes'' de l'espace d'états peut rendre le problème non-markovien). Il existe des techniques de découpage automatique [Munos, 1999], mais elles restent subordonnées au cas d'un MDP et n'ont montré leur efficacité que pour des problèmes ``jouets''. Mais, dans la pratique, il n'existe aucun critère permettant, à partir d'un ensemble de signaux perceptifs, d'induire un ensemble d'états adéquat pour résoudre à coup sûr un problème donné.
En fait, nous constatons que les formalismes existants déconnectent l'apprentissage d'une tâche de la faculté de percevoir, qui est programmée a priori (on détermine précisément la manière de former l'espace d'états du système). D'autre part, nous observons que l'expérience passée de l'entité apprenante n'est pas utilisée explicitement par l'algorithme d'AR afin de limiter l'étendue de l'espace d'exploration des solutions possibles. Des tentatives existent mais elles s'expriment par l'ajout d'un contexte approprié à l'algorithme d'AR: cet ajout ne fait pas partie intégrante du formalisme de l'AR. Or, l'utilisation du hasard impose des restrictions d'ordre pratique. En effet, si le signal de renforcement utilisé est binaire, la construction d'une politique de choix d'actions efficiente ne pourra débuter qu'au moment où une séquence d'actions donnant un résultat satisfaisant pour le problème donné (induit par le signal de renforcement) est découverte. Or, celle-ci s'effectue au hasard. Par conséquent, si la phase d'exploration de l'espace d'états n'est pas guidée par une certaine connaissance a priori du problème et si la probabilité de trouver au hasard une séquence satisfaisante est trop réduite, la durée préliminaire de l'apprentissage (durée écoulée avant la découverte de cette séquence) peut devenir prohibitive. Or, dans le cadre général, il est difficile d'estimer une moyenne de cette durée pour un problème particulier (à moins de savoir calculer la probabilité de découverte d'une séquence satisfaisante), avant de débuter l'apprentissage.
Enfin, certains paramètres internes à l'algorithme ont une relation directe avec ce facteur temps: l'évolution du pas d'apprentissage, guidant l'ampleur de la modification de la fonction valeur, est soumise à une condition théorique 8 pour garantir la convergence de l'algorithme (en temps infini) tout en préservant la possibilité d'adaptation à un changement de l'environnement. En outre, si le problème exploration/exploitation est guidé par une probabilité de choix issue d'une fonction de Boltzmann, la décroissance du facteur de température va influer sur le résultat de l'apprentissage. L'évolution de ces deux paramètres doit se faire en accord avec la durée préliminaire, mais aussi en accord avec la phase qui suit, où on va améliorer de proche en proche la solution trouvée initialement au hasard. Par conséquent, le fait de fixer l'évolution des paramètres induit des présupposés sur la durée d'établissement d'une ``bonne'' solution, ce que l'utilisateur n'a pas les moyens de connaître dans le cas général, du moins avant d'avoir expérimenté l'apprentissage et constaté le résultat de celui-ci.
Une autre difficulté pratique liée à la décroissance du pas d'apprentissage et du facteur de température (si ce choix pour la politique d'exploration/exploitation a été effectué) est le ralentissement de l'adaptation face à la découverte de nouveaux états du système ou à une modification de l'environnement. Le caractère incrémental n'est pas touché théoriquement en lui-même, puisque l'adaptation est toujours possible, à n'importe quel moment de l'apprentissage; mais, la réactivité du système à l'apparition d'un fait nouveau devient de plus en plus lente. La faculté d'incrémentalité perd alors son intérêt d'un point de vue pratique. Dans ce cas, il faut pouvoir ``relancer'' l'apprentissage à intervalles de temps déterminés pour pallier cette difficulté inhérente à la volonté d'obtention d'une convergence vers un optimum. Or, on ne sait pas, dans le cas général, spécifier cette plage de temps, même si on peut le découvrir empiriquement dans un cas particulier.
Les remarques que nous avons notées ci-dessus n'ont pas un caractère exhaustif sur les difficultés qu'on peut rencontrer à l'utilisation d'algorithmes d'AR, et ne concernent que notre domaine d'applications. Toutefois, elles justifient en partie la conclusion que nous avons tirée de notre expérience d'utilisateur des méthodes d'AR, qui a conditionné le développement du travail inclus dans ce recueil. Nous constatons que les méthodes d'AR permettent effectivement de résoudre des problèmes, parfois complexes. Cependant, bien des aspects, intéressants en théorie, sont gommés en pratique. Le caractère le plus attrayant pour un utilisateur est la quantité minime de travail qu'il a à effectuer pour préparer l'apprentissage, ainsi que la non-obligation de connaître les mécanismes de fonctionnement de l'algorithme. Pourtant, l'apprentissage peut échouer, pour une des raisons que nous avons invoquées ci-dessus; il est alors nécessaire d'avoir une expérience suffisante de l'AR pour détecter d'où l'échec provient (tâche non triviale) et pour mettre en place un contexte plus ``adapté'' à la réussite de l'apprentissage (meilleure spécification des états, réglage des paramètres). Or, ces spécifications sont loin d'être intuitives dans le cas où des données perceptives issues de capteurs sont utilisées pour construire les états du système. D'autre part, il est captivant, a priori, de considérer qu'une tâche apprise par l'AR, donc guidée uniquement par l'objectif, puisse se construire au fil du temps pour épouser parfaitement l'environnement dans lequel elle est plongée,en s'adaptant aux modifications de celui-ci le cas échéant. Or, nous avons constaté que les méthodes d'AR ne permettent pas cette adaptation, en pratique, dans le cas général, sans que l'utilisateur ait une connaissance bien précise à propos de la dynamique de l'apprentissage dans le cas qui l'intéresse (cela étant lié à la valeur des paramètres internes à l'algorithme). Tout cela ne signifie pas que, pour chaque cas particulier, on ne puisse pas trouver une façon de résoudre le problème par l'AR. Mais nous constatons que la méthode est loin d'être aussi générale et facile d'accès qu'il n'y paraît au premier abord et que les problèmes doivent être traités au cas par cas, par essais/erreurs successifs de l'utilisateur (à moins que celui-ci n'ait une grande expérience de l'AR). Dans le champ d'applications qui nous intéresse plus particulièrement, ce qui manque essentiellement est le caractère prédictif et déterministe que l'utilisateur non spécialiste peut espérer attendre concernant le résultat de l'application d'une méthode ou d'un algorithme. Cela est dû au fait qu'il est difficile de savoir a priori si les hypothèses inhérentes à l'AR sont respectées ou non, surtout si on veut établir un système réactif à partir des données issues de capteurs.
Nous avons l'intime conviction que les problèmes d'apprentissage liés à la perception ne peuvent pas être facilement abordés en raison d'un manque de cohérence entre l'étude du traitement de la perception (aboutissant à la notion d'état perceptif), la mémorisation (conduisant à un élagage des possibilités offertes a priori à l'entité lors de son apprentissage) et de l'apprentissage proprement dit. En fait, cette incompatibilité est apparue depuis qu'il a été possible d'imiter mécaniquement des comportements intelligents humains. Ainsi, le concept d'intelligence est au centre d'un débat ouvert entre plusieurs disciplines scientifiques, mais aussi entre différents courants de pensée. Deux démarches coexistent, sans vraiment aboutir à de véritables synergies. D'une part, les études en biologie, neurologie ou en sciences cognitives visent à comprendre le fonctionnement du vivant en observant les caractéristiques physiologiques du cerveau ou en scrutant le comportement humain. D'autre part, une autre direction de recherche, qui adopte une démarche plus formalisée mais possédant des hypothèses très restrictives (traitement du signal, méthodes d'optimisation, etc.), consiste à reproduire, grâce à l'ordinateur, des facultés qu'on attribue généralement à l'intelligence humaine. Bien entendu, ces deux axes de recherche ne sont pas exclusifs l'un de l'autre: de nombreuses simulations illustrent le bien-fondé et les limites des modèles déduits de l'approche biologique ou comportementale, alors que les recherches visant à imiter des facultés humaines peuvent s'aider de modèles issus de travaux en biologie. Dans le cadre de l'AR, qui nous a concerné plus particulièrement, le terme ``renforcement'' possède une acception biologique, liée aux découvertes de Pavlov. Cependant, on constate que ce n'est pas la démarche explicative, de plus en plus fine, des processus cognitifs qui a permis les avancées les plus notables dans l'élaboration de programmes ``intelligents'' performants. En outre, le besoin de performance a tendance à déconnecter un modèle, qui pouvait être au départ biologiquement plausible mais dont les résultats étaient moyennement satisfaisants, de ses bases originelles. Ce phénomène est très clair pour l'AR.
Lorsque nous avons commencé notre travail avec l'AR, c'était exclusivement dans un contexte applicatif: permettre d'améliorer les performances d'apprentissage d'un ensemble de tâches par un robot mobile, spécifier les améliorations éventuellement apportées et comparer la ou les méthodes trouvées avec des méthodes existantes, en se basant sur les résultats de l'apprentissage. Cependant, cette approche, qu'on peut qualifier de fonctionnaliste dans le sens où elle ne s'intéresse qu'à une interprétation du résultat observable de l'expérience (une mesure permettant de qualifier la performance du système), peut biaiser la manière dont on juge les performances intrinsèques d'une méthode d'apprentissage. En effet, le résultat final (apprentissage effectif ou échec, durée de l'apprentissage) dépend aussi bien de la méthode d'apprentissage elle-même que de l'élaboration d'un contexte adapté au bon fonctionnement de celle-ci (c'est-à-dire permettant de respecter les hypothèses de bon fonctionnement inhérentes à la méthode). Ainsi, à partir d'un simple résultat sur un problème donné, la seule conclusion que nous sommes capables de déduire est la qualité de l'adéquation contexte/méthode. Or, dans le cas général, on considère que les données apportées au système apprenant font partie du contexte de ce dernier; en particulier, on fait l'hypothèse que ces données, telles qu'elles sont présentées au système, permettront à ce dernier de rester dans un cadre de ``bon fonctionnement''. Or, lorsqu'on utilise des données imprécises ou incertaines, la construction du contexte de fonctionnement de l'algorithme d'apprentissage nécessitera l'utilisation des connaissances sur l'environnement dans lequel va évoluer le robot et sur le robot lui-même (nature des obstacles, caractéristiques des capteurs) pour simplifier le problème initial. Mais cette démarche induit des erreurs ou des manques, dans le cas usuel où l'ensemble du problème (environnement, robot et interaction entre les deux) ne peut pas être modélisé d'une manière assez précise: cela se traduit entre autres par l'impossibilité d'établir parfaitement des catégories perceptives auxquelles le robot ou la machine associe un comportement déterminé. Ainsi, l'exécution de l'algorithme d'apprentissage en dehors d'un certain contexte de fonctionnement que le programmeur ne peut pas en général déterminer précisément a priori conduit à des erreurs d'exécution que l'algorithme n'est pas en mesure de corriger par lui-même. C'est justement parce que prévoir toutes les configurations possibles d'un problème utilisant la perception est une tâche trop lourde, voire irréalisable, que les techniques d'apprentissage incrémental ont un sérieux intérêt. Comme nous l'avons vu au début de ce préliminaire, les techniques d'AR possèdent théoriquement ces atouts, puisqu'elles permettent à une machine, par l'expérience c'est-à-dire par essais/erreurs successifs, de découvrir progressivement l'intégralité du contexte dans lequel elle évolue réellement (ici et maintenant) et de s'y adapter en fonction d'un objectif précis. Un changement de ce contexte devra amener l'entité à modifier son comportement en conséquence (caractère d'incrémentalité). Mais, nous avons constaté que cela était loin d'être aussi simple lorsque la gestion de la perception est contextuelle, c'est-à-dire qu'elle ne fait pas partie intégrante de l'algorithme d'apprentissage.
C'est pourquoi nous pensons que le cadre actuel, dans lequel la perception, la mémorisation et l'apprentissage d'une stratégie répondant à un problème précis, ne sont pas gérés d'une manière globale, à partir d'une base théorique identique, explique en grande partie les résultats mitigés dans des domaines où les capacités à percevoir et à reconnaître des situations mémorisées jouent un grand rôle et conditionnent très fortement l'apprentissage de tâches.
Le thème central de notre travail est la recherche d'une spécification de l'information perceptive et des mécanismes internes à l'entité permettant de l'obtenir activement. Notre analyse préliminaire nous amène à penser que l'information perceptive est beaucoup plus qu'une somme de données reçues par l'entité: elle correspond plus au résultat d'un processus dynamique. Ainsi, notre objectif est de réunir dans un même cadre théorique les trois composantes qui semblent liées pratiquement: perception, mémorisation (reconnaissance de situations) et capacité d'atteinte d'objectifs. Ce projet est ambitieux et novateur, dans la mesure où il s'agit de construire intégralement ce cadre, sans l'aide préalable d'une formalisation mathématique existante. Nous sommes conscients que le risque inhérent à cette démarche est d'aboutir à une impasse, d'ordre théorique ou pratique.
Notre démarche vise à être aussi cohérente que possible avec des caractéristiques biologiques, physiologiques et comportementales humaines. Cette cohérence ne s'exprimera pas au niveau des matériaux permettant l'élaboration de notre raisonnement (modèle d'une partie ou d'une caractéristique du cerveau), mais au niveau des particularités engendrées par ce dernier, c'est-à-dire au niveau de la nature des résultats que ce raisonnement contribue à générer.
Ainsi, il s'agit de définir un cadre théorique, cohérent avec des caractéristiques biologiques, physiologique ou comportementales humaines au niveau des résultats qu'il engendre. Nous avons pour objectif de réunir dans un même formalisme les processus de perception, de mémorisation et d'atteinte d'objectifs.
Nous nous limiterons à l'étude de phénomènes n'impliquant aucunement des capacités intellectuelles conscientes (utilisation consciente de connaissances). En outre, le terme ``atteinte d'objectif'' est ici dénué de toute notion d'optimalité, prise au sens strict et nous précisons que ``atteinte d'objectif'' se résume au respect à tout moment d'un ensemble de contraintes (viabilité). Pour cela, on suppose qu'on possède un signal de renforcement binaire, indiquant à tout moment si l'ensemble des contraintes est respecté ou non.
Nous nous intéresserons plus particulièrement aux mécanismes qui régissent l'interaction d'une entité avec son environnement, c'est-à-dire la manière dont celle-ci perçoit le monde extérieur à travers sa propre expérience (sa mémoire) et sa propre condition physique (moyens de perception et moyens d'action sur le monde). En cela, nous suivons simplement les constatations apportées par Damasio9 sur l'interdépendance du cerveau et des organes sensorimoteurs. Dans ce cadre, nous verrons que le mot-clé est ``cohérence'': notre recherche aboutit en particulier au fait qu'il doit exister des conditions nécessaires sur la nature des signaux perceptifs mais aussi sur l'état de la mémoire de l'entité pour que ceux-ci puissent être mémorisés, puis utilisés dans un objectif précis. En outre, nous serons amenés à postuler que ce phénomène de cohérence implique que les processus de perception et de mémorisation soient dynamiques: une information utilisable par l'entité est obtenue au bout d'une durée non nulle à partir de plusieurs données perceptives; il en va de même pour la faculté de reconnaissance d'une situation.
Nous définirons les notions d'observabilité d'un fait et de possibilité de mémorisation de ce dernier à partir de considérations statistiques:
Un fait sera considéré comme étant observable s'il suit certaines régularités dont l'apparition due uniquement au hasard est statistiquement très improbable.
Ainsi, le caractère d'observabilité est associé à une certitude concernant la nature de ce qui est observé (et qui dépend des régularités évoquées ci-dessus): l'information perceptive contient en elle-même se caractère de certitude. D'autre part, nous montrerons comment la mémoire apporte une aide à la perception dans une tâche routinière (apprise) en permettant à l'entité d'anticiper à tout moment ce qui va probablement se passer. Nous constaterons que le problème de respect de contraintes utilise ce phénomène d'anticipation à partir d'un spectre perceptif dans lequel le signal binaire de renforcement sert de filtre.
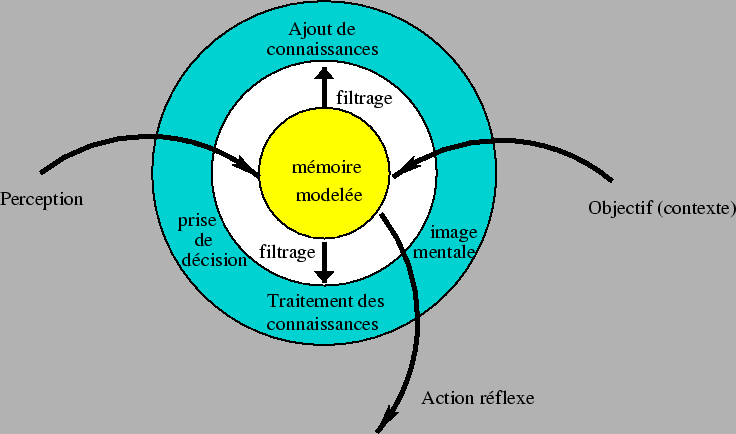
Nous pensons que le phénomène d'apprentissage est commun aux processus de perception, de mémorisation et d'atteinte d'objectif. Ainsi, notre hypothèse fondatrice est que l'acquisition de connaissances (mémorisation) dans un domaine particulier, utilisant forcément des canaux perceptifs propres à la faculté à mettre en oeuvre, nécessite au préalable que la mémoire soit ``modelée'' d'une manière spécifique au problème posé (voir la figure 1); ce ``modelage'' est un travail interne de l'apprenant, en réponse aux signaux qu'il reçoit de son environnement et aux actions qu'il exécute en réponse à ces stimulations. Nous supposons que le résultat de ce travail interne est la construction d'une ``structure mentale'' capable de mémoriser des informations concernant le problème. L'objectif de cette structuration est le développement de la faculté d'anticipation que nous venons d'évoquer ci-dessus, nécessaire selon nous à la résolution des problèmes d'atteinte d'objectif. En outre, elle dépend des moyens spécifiques à l'apprenant pour percevoir son environnement, agir sur celui-ci et juger de la bonne adéquation perception/action.
De ce fait, nous admettons les deux assertions suivantes:
La mémoire n'est pas un contenant dont la structure est figée (comme l'est la mémoire informatique), mais, au contraire, elle ne peut être séparée ni du contenu (l'information à mémoriser), ni des moyens de perception et d'action propres à l'apprenant.
Le processus de modelage de la mémoire est une base commune à l'ensemble des canaux de perception et des moyens d'action de l'apprenant.
Par conséquent, nous admettons que la mémoire est un point de rencontre obligé entre la perception (prise au sens large, c'est-à-dire incluant la perception de signaux internes tels que le signal de renforcement), les moyens d'action et un contexte ou un objectif précis: elle possède une faculté d'adaptation qui lui permet de transformer sa structure en réponse à l'expérience de l'entité apprenante. En somme, nous acceptons l'hypothèse que la mémoire est polymorphe, et que ce polymorphisme est la manifestation de capacités d'adaptation de l'apprenant, non seulement par rapport à son environnement mais aussi par rapport à ses propres capacités de perception et d'action que celui-ci ne sait pas gérer a priori.
Comme le titre de ce mémoire l'indique, le travail que nous présentons dans les pages qui suivent n'est pas un ``produit fini'': il s'agit d'une ébauche dont l'objectif intrinsèque est de proposer un axe de recherche et de le justifier. Beaucoup de travail reste à accomplir, tant d'un point de vue théorique qu'applicatif. Dans ce texte, nous avons souhaité montrer le bien-fondé de l'axe de recherche proposé, tout en indiquant, lors de chacun des choix que nous avons effectués, les limitations et les insuffisances que celui-ci engendre.
Notre travail va consister tout d'abord à réunir un ensemble d'hypothèses issues de faits liés au fonctionnement mental humain, sans bases mathématiques préalables, afin d'esquisser une justification de nos assertions. Néanmoins, même si nous évoquons l'importance de la structuration de la mémoire, nous rappelons que notre travail n'est pas fondé sur les bases biologiques de la structuration des connexions entre les neurones du cerveau.
La qualité du résultat obtenu sera jugée bien sûr sur la capacité de la machine apprenante à réaliser un comportement donné en un temps raisonnable, mais également sur les critères suivants:
|
L'exposé contenu dans ce recueil se compose de trois parties, s'articulant autour de la recherche d'un formalisme commun aux processus de perception, de mémorisation et d'atteinte d'objectif. Celles-ci sont des approches, à des niveaux différents, du même problème. La première partie (chapitre 1) est une réflexion informelle sur la machine intelligente, débutant par une analyse de différents courants de pensée ayant influencé ce domaine de recherche (section 1), se poursuit par un exposé des hypothèses fondatrices de notre travail (section 2), puis par l'ébauche d'un axe de recherche (section 3). La seconde partie (chapitres 2, 3 et 4) a pour objet de formaliser la réflexion menée dans la première partie, ce qui aboutit à la création d'un algorithme d'apprentissage. Le chapitre 2 montre en particulier l'évolution de notre approche de la formalisation des hypothèses de travail. Enfin, la troisième partie (chapitre 5) conclut le travail relaté dans ce recueil. En particulier, elle fait état du plan de travail que nous allons adopter afin de poursuivre l'exploration de l'axe de recherche que nous avons initié. En outre, elle met en exergue l'objectif applicatif qui sous-tend notre travail.