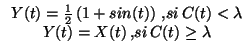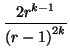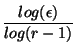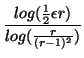Problème _s
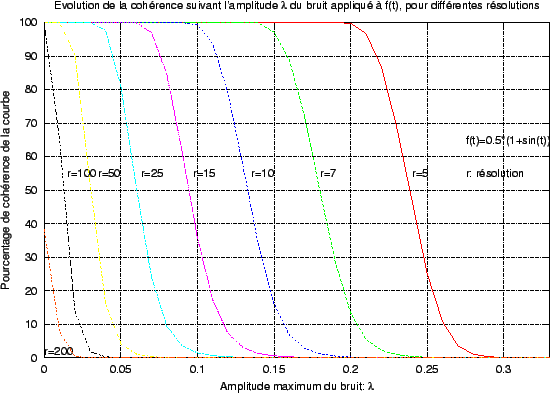
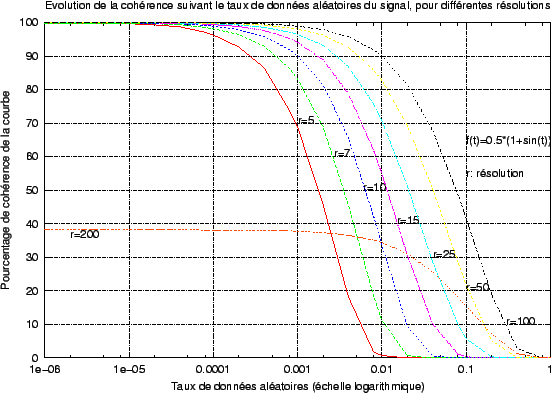
: le nombre de confirmations consécutives est très grand. Par conséquent, lorsque le signal varie rapidement ou lorsque le taux d'échantillonnage est trop faible, le nombre de mesures incluses dans un segment devient trop faible pour apporter une information certaine, puisque le nombre de confirmations nécessaires n'est pas atteint. Le résultat est un ``trou'' dans la suite des informations que notre technique apporte. La figure
2.15 illustre ce fait.
Problème _s
: lorsque l'amplitude maximum du bruit dépasse la taille d'un segment, la cohérence est rompue, même si la probabilité pour que l'écart entre deux mesures dépasse la taille de ce segment est très faible.