Pour la première expérimentation, nous avons soumis le processus d'élagage à un signal de densité U[0,1] pendant 10 millions d'itérations. Nous avons constaté que, pendant ce temps, la valeur du signal de certitude reste constamment à 0, ce qui est cohérent avec la théorie. Cela tend à confirmer que le dimensionnement des focus est correct.
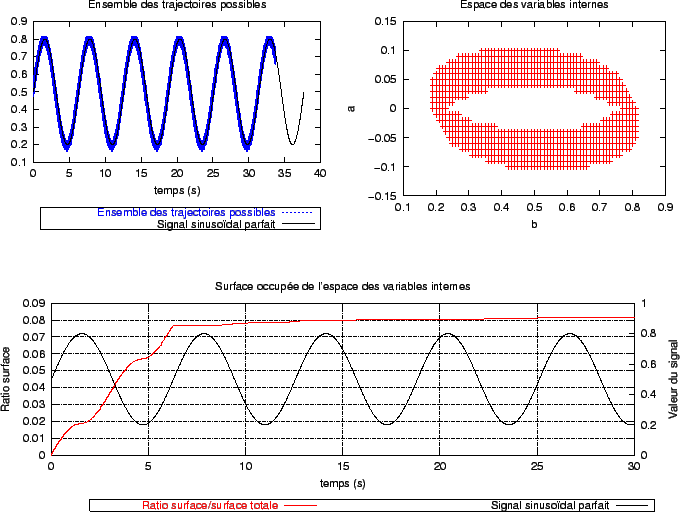
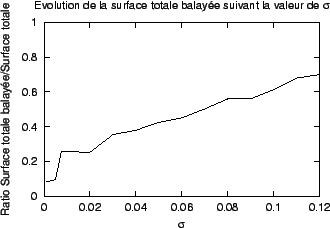
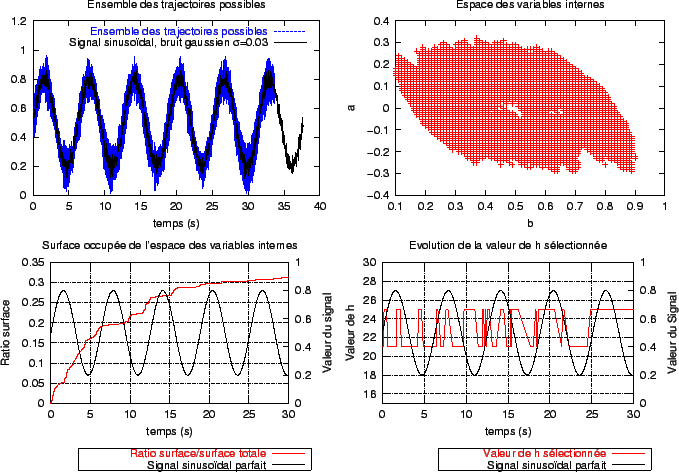
La figure 3.5 montre les résultats de la deuxième expérimentation en utilisant un signal sinusoïdal parfait (non bruité), alors que la figure 3.6 relate la même expérience pour un signal sinusoïdal bruité artificiellement. L'aire de la surface totale balayée au cours du temps est notablement plus importante dans le cas où le signal est bruité: cette augmentation s'explique par un accroissement du nombre des scenarii possibles pour une valeur de h donnée, mais aussi par une augmentation des valeurs de h utilisées. D'autre part, l'évolution de la surface totale balayée n'est pas stoppée après la première période du signal: il faut plus de temps pour voir apparaître l'ensemble des scenarii possibles. Cela signifie en particulier que, pour une même configuration du signal, certains scenarii possèdent une probabilité d'être validés qui n'est pas très proche de 0 ou très proche de 1. Or, comme nous l'avons déjà remarqué au cours du chapitre 2, il existe une certaine ``liberté'' des trajectoires des focus autour de la trajectoire suivie par le maximum de la densité de probabilité du signal: celle-ci se traduit par l'existence de scenarii ``limites''. Ceux-ci sont en partie à l'origine de l'importance de la surface de l'espace des variables internes balayée au cours du temps ( figure 3.7). Cette surface devient rapidement très importante et la restitution du signal à partir de l'ensemble des scenarii validés au cours du temps devient grossière.
|
|
Ces premières expériences amènent deux questions:
La réponse à ces deux questions est délicate, en fait. En effet, notre attention se porte vers la ``qualité'' de la reconstitution du signal et, pour parvenir à une meilleure qualité, nous sommes tentés d'échafauder des critères de sélection non justifiés par nos hypothèses fondatrices et, en particulier, par l'exigence d'une quasi-certitude (première question). D'autre part, nous voyons le mécanisme de bouclage interne comme une possibilité d'améliorer également le ``rendu'' de la reconstitution du signal (deuxième question).
Avant de donner un exemple de réponse concrète à ces deux questions, nous remarquons que cette volonté d'obtenir une reconstitution de bonne qualité signifie que nous souhaitons que les données perçues soient filtrées de manière à obtenir, au bout du compte, un ensemble de points formant une trajectoire proche de la trajectoire théorique d'un signal parfait (c'est-à-dire une sinusoïde, dans notre exemple). Or, cet objectif n'est pas conforme à ce que nous souhaitons, car il met la mémoire ``hors-jeu''. De plus, l'idée même que certains scenarii soient plus valides que d'autres remet en cause le coté binaire du processus d'élagage (tous les scenarii validés sont de même qualité ``bonne'' alors que les scenarii invalidés possèdent une qualité ``mauvaise'').
Admettons que nous souhaitions donner une réponse à ces deux questions. Nous avons remarqué qu'à un instant t, un intervalle élémentaire peut être sélectionné par plusieurs scenarii (paragraphe 3.1.5). Si, pour cet instant t, nous comptons pour chaque intervalle élémentaire le nombre de sélections, nous pouvons établir une courbe analogue à celle d'une densité de probabilité de présence du signal à l'instant t (figure 3.9, en haut). À partir de ces données, on peut déterminer la valeur du signal reconstruit en utilisant une probabilité de choix dépendant du nombre de sélection de chacun des intervalles élémentaires (voir l'algorithme 3.2 ). Le signal reconstruit peut ainsi être réinjecté au processus d'élagage. La figure 3.9 montre que le signal d'origine est sensiblement amélioré par cette méthode; en particulier, les points pris aléatoirement (figures de droite) sont éliminés dès la première itération. De plus, il faut noter qu'au bout de deux ou trois itérations de l'algorithme de bouclage, il n'existe plus de différence de ``qualité'' entre deux reconstitutions successives. Toutefois, la ``forme'' du signal après ce bouclage peut être relativement différente de celle du signal sinusoïdal théorique (figure en bas à droite). Cette constatation confirme nos craintes évoquées plus haut: tout comme les données perceptives brutes, les données reconstruites ne peuvent pas être utilisées dans un processus visant à discriminer plusieurs catégories de signaux suivant leur ``forme'' spécifique, avec une quasi-certitude. Cette discrimination doit être effectuée à l'aide du processus d'anticipation, que nous n'avons pas fait intervenir dans ces expériences (
UPinit(t) est égal à l'univers des possibilités total à chaque instant t).
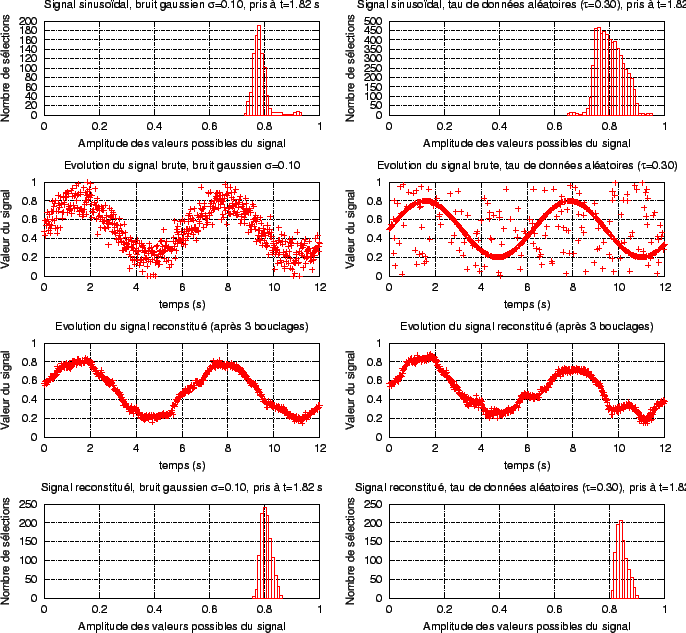
Le procédé de reconstruction du signal explicité dans le paragraphe 3.1.5 considère qu'à chaque instant t, la valeur du signal peut être dans chacun des intervalles élémentaires touchés par au moins un scenario. Les deux figures du haut montrent que, bien que l'étalement des valeurs possibles (à l'instant t=1.82 s) soit important, il existe un pic relativement étroit, montrant que certains intervalles élémentaires sont beaucoup plus sélectionnés que d'autres au cours du temps, pour cet instant précis (t=1.82 s). À l'issue de trois itérations de l'algorithme de bouclage, nous nous apercevons que l'étalement des valeurs possibles est plus étroit (figures du bas), toujours pour l'instant t=1.82 s. Par contre, le signal reconstitué peut être déformé par rapport au signal théorique (figures de droite). |
Abordons à présent la troisième expérience préliminaire, donnant les limites de notre algorithme de choix de h (algorithme 2.3, page ![]() ). Nous avions déjà mis en évidence certaines limitations (conclusion du chapitre 2). Cependant, l'algorithme d'élagage développé dans le chapitre précédent (algorithme 2.1, page
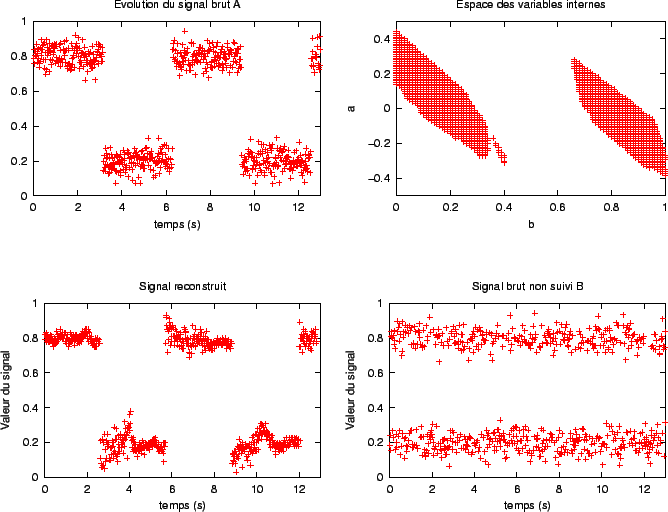
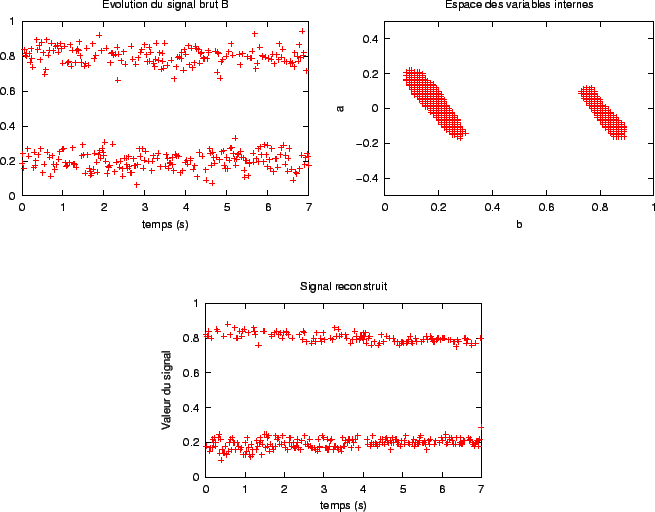
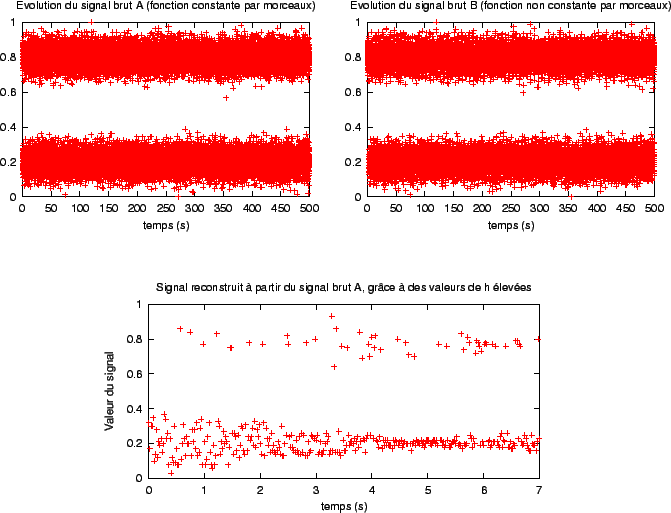
). Nous avions déjà mis en évidence certaines limitations (conclusion du chapitre 2). Cependant, l'algorithme d'élagage développé dans le chapitre précédent (algorithme 2.1, page ![]() ) n'était pas assez général pour constater d'autres limitations. En particulier, celui-ci ne pouvait pas suivre un signal ``discontinu''. L'exemple donné par la figure 3.10 montre que l'algorithme présenté dans ce chapitre peut suivre de tels signaux, mais sous certaines restrictions, qui dépendent de l'algorithme 2.3. L'exemple qui ``piège'' l'algorithme 2.3 montre un signal construit à partir d'une fonction non continue par morceau. Or, le signal brut ne possède pas une densité de probabilité U[0,1]; l'échec est dû au fait que les valeurs de h imposées par cet algorithme sont trop faibles (on ne prend pas assez de ``hauteur'' pour regarder le signal). En effet, la figure 3.11 montre qu'il est possible de suivre ce signal, en choisissant des valeurs de h plus grandes.
) n'était pas assez général pour constater d'autres limitations. En particulier, celui-ci ne pouvait pas suivre un signal ``discontinu''. L'exemple donné par la figure 3.10 montre que l'algorithme présenté dans ce chapitre peut suivre de tels signaux, mais sous certaines restrictions, qui dépendent de l'algorithme 2.3. L'exemple qui ``piège'' l'algorithme 2.3 montre un signal construit à partir d'une fonction non continue par morceau. Or, le signal brut ne possède pas une densité de probabilité U[0,1]; l'échec est dû au fait que les valeurs de h imposées par cet algorithme sont trop faibles (on ne prend pas assez de ``hauteur'' pour regarder le signal). En effet, la figure 3.11 montre qu'il est possible de suivre ce signal, en choisissant des valeurs de h plus grandes.
|
|
Les deux derniers signaux bruts étudiés (l'un constant par morceaux et l'autre non continu par morceaux) permettent de donner un bon exemple de l'importance du choix de h dans un problème de discrimination entre deux signaux (problème inclus dans le processus de mémorisation). C'est l'objet de notre dernière expérience préliminaire. Les deux signaux sont construits à partir de fonctions différentes. Pourtant, les occupations de l'espace des variables internes sont très semblables (voir les figures 3.10 et 3.11). En fait, les plages de valeurs touchées sont identiques pour les deux signaux (autour de 0.2 et autour de 0.8), ce qui se traduit par deux ``taches'' centrées autour de b=0.2 et b=0.8 dans l'espace des variables internes. La différence est que dans un cas, ces deux zones de l'espace des variables internes sont activées l'une après l'autre, alors que dans l'autre cas, elles sont activées simultanément. Or, la notion de simultanéité (ou de précédence), qui s'exprime avec une dimension temporelle, semble liée au fait que nous avons l'impression de visualiser deux ou une seule courbe sur les graphiques d'évolution du signal (dimension spatiale). Ainsi, la ``précédence'', constatée pour le signal issu d'une fonction constante par morceaux, dépend de la ``hauteur'' avec laquelle on regarde le signal (donc de la valeur de h). La figure 3.12 montre que si on regarde les deux signaux d'assez haut, on ne peut pas visuellement les différencier. En parallèle, si on reprend le même ensemble des valeurs de h sélectionnées pour traiter le signal dont la fonction n'est pas continue par morceaux, et qu'on l'applique au signal issu d'une fonction constante par morceaux, on constate qu'il n'y a plus de précédence entre zones de l'espace des variables internes activées autour 0.2 et celles activées autour de 0.8 : vu à cette ``hauteur'', ce signal est comparable à celui qui n'est pas continu par morceaux.
|
Ces premières expériences nous permettent de dégager des remarques importantes pour poursuivre notre travail, donnant lieu à une nouvelle proposition spécifiant mieux les contours des processus de perception et de mémorisation:
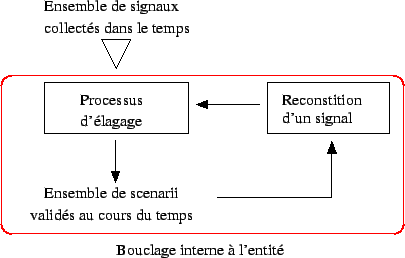
À l'issue de ces expériences préliminaires, nous pouvons spécifier plus précisément le contexte du processus de mémorisation: l'algorithme 2.3, dont le but était de sélectionner h automatiquement, sans avoir recours au processus de mémorisation, a montré ses limites. Cela nous conduit à abandonner cette piste et nous suggère la proposition suivante:
![\begin{algo}
% latex2html id marker 4105
[b]
Notations:
\begin{itemize}
\item Le...
...thme de reconstitution d'un signal à partir d'un ensemble de scenarii}\end{algo}](img168.gif)