Proposition _s
Pour tout l dans ]0,1[ tel que toutes les
probabilités
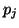
sont strictement supérieures à l, alors il
existe des valeurs de h et de i telles que (h,i,l) vérifie les
deux contraintes associées à CO. D'autre part, pour tout l dans
]0,1[ tel que toutes les probabilités
sont inférieures ou
égales à l, il n'existe pas de valeurs pour h et i telles que
(h,i,l) vérifie les deux contraintes de CO à la fois.
![\includegraphics[]{fig/normale.eps}](img329.png)
![\includegraphics[]{fig/seg_out.eps}](img331.png)
![\includegraphics[]{fig/sensib.eps}](img333.png)
![\includegraphics[]{fig/sensib_gau.eps}](img335.png)
![\includegraphics[]{fig/ex_dens.eps}](img326.png)