|
CbMU |
Description de la tâche |
signaux d'entrée |
commandes possibles |
contrainte associée |
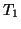 |
Suivi mur gauche |
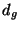 , ,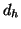 , ,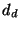 |
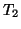 , ,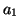 , ,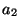 |
NPSC,MG |
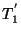 |
Suivi mur droite |
,, |
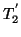 ,, ,,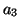 |
NPSC,MD |
|
|
Suivi mur convexe gauche |
|
,,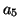 |
NPSC,MG |
|
|
Suivi mur convexe droite |
|
,, |
NPSC,MD |
NPSC: ``Ne pas se cogner'', ``MG'': être assez près d'un mur sur
sa gauche, ``MD'': être assez près d'un mur sur sa droite.
|


![\includegraphics[]{fig/hierarchie.eps}](img219.png)
![\includegraphics[]{fig/preparation.eps}](img189.png)